目次
レプリケーションは1 つの MySQL サーバ (マスタ) にあるデータベースを別のサーバ (スレーブ) に複製できるレプリケーション機能があります。レプリケーションは非同期、つまり複製スレーブをマスタから更新するときに常時接続である必要がなく、接続距離が離れていても更新することができ、ダイヤルアップなどの一時的なソリューションとしても利用することができます。コンフィギュレーションによっては、すべてのデータベースまたは選択したデータベースを複製でき、さらにデータベース内で選択したテーブルを取り込むこともできます。
以下は、MySQL のレプリケーションの使用例です。
スケールアウト ソリューション - パフォーマンス向上のために複数のスレーブにロードを分散します。この環境では、すべての書き込みと更新をマスタ サーバで実行する必要があります。読み込みの際には、一つ以上のスレーブでの実行が必要になる場合があります。このモデルは、スレーブ数が増加しても読み込みスピードが劇的に向上し、さらにマスタが更新専用になるために書き込み性能も向上します。
データ セキュリティ - スレーブでデータを複製するため、スレーブは複製プロセスを一時停止することでき、後続のマスタデータを破壊することなくスレーブにバックアップ サービスを実行できます。
分析 ‐ マスタでライブ データの作成を行い、スレーブで情報分析を行うため、マスタのパフォーマンスに支障をきたしません。
長距離データ配布 − マスタへの常時接続を不要とするため、別の場所でメイン データを利用したいときなどに、複製をデータのローカル コピーとして使用できます。
MySQL の レプリケーションは、一方向性の非同期複製のサポートを特徴とし、一つのサーバがマスタとして機能し、別のサーバがスレーブとして機能します。これは、 MySQL クラスタ の特徴である同期複製とは対照的です。(参照 章?14. MySQL Cluster)
二つのサーバ間でレプリケーションを設定するには、いくつかのソリューションがあり、データ形状や使用しているエンジン タイプにあわせて最適設定することが可能です。利用可能なオプションの詳細については、項5.1.1. 「レプリケーションのセットアップ方法」 を参照してください。
レプリケーション形式には、SQL すべてのステートメントを複製する Statement Based Replication (SBR: クエリ ベース レプリケーション)、変更があった row (行列) だけを複製する Row Based Replication (RBR: 行ベース レプリケーション) の 2 種類があります。また、第 3 の形式、Mixed Based Replication (MBR) を使用することも可能です。これは、MySQL 5.1.14 以上のデフォルト モードです。レプリケーション形式の詳細については、項5.1.2. 「レプリケーション フォーマット」 を参照してください。
レプリケーションは、様々なオプションと変数によってコントロールされます。これらは、レプリケーション、タイムアウト、データベース、フィルタなど、データベースやテーブルに適用する操作の中核をコントロールします。利用可能なオプション詳細については、項5.1.3. 「レプリケーションのオプションと変数」 を参照してください。
パフォーマンス向上に関わる課題、異なるデータベースのバックアップ サポート、またはシステム不良を回避するための保全ソリューションの一部としてなど、様々な問題を解決するためにレプリケーションを活用できます。ソリューションに関する詳細については、項5.3. 「レプリケーション ソリューション」 を参照してください。
レプリケーション機能の詳細、バージョン間の互換性、アップグレード、既知問題およびソリューション、FAQなど、レプリケーション作業中に異なるデータ タイプおよびクエリがどのように処理されるかに関する情報は、項5.4. 「レプリケーション ノートとヒント」 を参照してください。
レプリケーションの実行、レプリケーションの手順、バイナリ ログ内容とその処理、バックグラウンド スレッド、そしてステートメント (クエリ) をどのように記録するかを決めるオプションに関する詳細は、項5.5. 「レプリケーションの実装」 を参照してください。
MySQL Enterprise MySQL Network Monitoring and Advisory Service では、レプリケーションに関する問題について迅速なフィードバックを提供する多数のアドバイザーを提供しています。詳細については、http://www-jp.mysql.com/products/enterprise/advisors.htmlをご覧ください。
MySQL のサーバ間におけるレプリケーションは、バイナリのロギング メカニズムを使用して行います。マスタ (データベース変更元) として機能している MySQL インスタンスは、データベースへの更新および変更をバイナリ ログに書き込みます。バイナリ ログの情報はデータベースでの変更記録に従い、異なるロギング フォーマットに格納されます。スレーブを設定して、マスタからのバイナリ ログを読み込み、そして、スレーブのローカル データベースにあるバイナリ ログでのイベント実行を行います。
このシナリオでのマスタには、データ処理能力がありません。バイナリ ロギングを実行可能にした後、すべてのステートメントはバイナリ ログへの記録になります。それぞれのスレーブがバイナリ ログの全内容のコピーを受信します。スレーブは、バイナリ ログのどのステートメントを実行するべきかを決定する役割を担い、マスタに特定のイベントだけをログするようには設定できません。指定がない限り、マスタのバイナリ ログのすべてのイベントがスレーブでの実行対象になります。必要に応じて、スレーブが特定のデータベースまたはテーブルに該当するイベントだけを処理するように設定できます。
スレーブは、バイナリ ログ ファイルと位置と読み込みおよび処理したログ ファイル内での記録を保持します。これは、複数のスレーブがマスタに接続することができ、同一のバイナリ ログで異なる部分を実行できます。スレーブはこのプロセスをコンロトールするため、それぞれのスレーブがマスタと接続または未接続の状態でも、マスタのオペレーションに影響することはありません。そして、それぞれのスレーブがバイナリ ログ内の位置を記憶しているため、スレーブが未接続の場合でも、再接続して切断前の記録位置から継続してキャッチアップすることができます。
マスタとそれぞれのスレーブの両方をユニーク ID
で設定 (server-id オプション)
する必要があります。さらに、スレーブはファイル内のマスタ
ホスト名、ログ
ファイル名、位置などの情報で設定します。これらの詳細は、CHANGE
MASTER を使用して、MySQL
セッション内からコントロールできます。詳細は、master.info
ファイル内にあります。
この章では、レプリケーション環境に必要なセットアップとコンフィギュレーションを示し、新たなレプリケーション環境を作成するためのステップ バイ ステップの手順が記されています。この章の主な内容は次の通りです。
2 つ以上のサーバでレプリケーションを行うためのガイドは、項5.1.1. 「レプリケーションのセットアップ方法」 を参照してください。この章はシステムのセットアップについて説明し、スレーブとマスタ間でのデータ コピー方法を提供します。
バイナリ ログのイベントはいくつかのフォーマットで記録します。このフォーマットをステートメント ベース レプリケーション (SBR) あるいは 行ベース レプリケーション (RBR) と呼びます。第三のフォーマットは、ミックス レプリケーション (MIXED) で、SBR と RBR レプリケーションを自動的に使い分け、適切に SBR と RBRの両方のフォーマットの利点を活用します。フォーマットに関しては、項5.1.2. 「レプリケーション フォーマット」 を参照してください。
レプリケーションにおける様々なコンフィギュレーションのオプションと変数に関する詳細は 項5.1.3. 「レプリケーションのオプションと変数」 を参照してください。
レプリケーションを開始すると、そのプロセスで管理権限と監視が必要になります。実行するときの共通タスクに関するアドバイスは 項5.1.4. 「レプリケーションでの管理タスク」 を参照してください。
- 5.1.1.1. レプリケーション ユーザの作成
- 5.1.1.2. レプリケーション マスタのコンフィギュレーション設定
- 5.1.1.3. レプリケーション スレーブのコンフィギュレーション設定
- 5.1.1.4. マスタ レプリケーション情報の取得
- 5.1.1.5.
mysqldumpを使用したデータ スナップショットの制作 - 5.1.1.6. 生データ ファイルでデータ スナップショットの作成
- 5.1.1.7. 新たなマスタとスレーブのレプリケーション セットアップ
- 5.1.1.8. 既存データでのレプリケーション セットアップ
- 5.1.1.9. 既存のレプリケーション環境へのスレーブ追加
- 5.1.1.10. マスタ コンフィギュレーションのスレーブでの設定
この章は、MySQL サーバのレプリケーションを完全に行うためのセットアップについて説明します。レプリケーションのセットアップには様々な方法があり、レプリケーションをどのようにセットアップするか、そしてマスタのデータベースにデータがすでに存在するかどうかにより、その方法が変わります。
すべてのレプリケーション セットアップに必要とされる一般的なタスクは次の通りです。
認証用に独立したユーザを作成する。これは、スレーブがマスタのバイナリ ログを複製するために読み込むときに使用する。項5.1.1.1. 「レプリケーション ユーザの作成」 を参照。
バイナリ ログをサポートするためにマスタを設定し、ユニーク ID を設定する。項5.1.1.2. 「レプリケーション マスタのコンフィギュレーション設定」 参照。
マスタと接続するそれぞれのスレーブでユニーク ID を設定する。項5.1.1.3. 「レプリケーション スレーブのコンフィギュレーション設定」 を参照。
データ スナップショットまたはレプリケーションを開始する前に、マスタのバイナリ ログの位置を記録する。この情報はスレーブを設定するときに必要になり、これによりスレーブはバイナリ ログ内のどこからイベントを実行するかを認識する。項5.1.1.4. 「マスタ レプリケーション情報の取得」 を参照。
すでにマスタにデータがある場合、スレーブと元データを同期化し、データベースのデータ スナップショットを作成する。スナップショットには、
mysqldumpを使用する (項5.1.1.5. 「mysqldumpを使用したデータ スナップショットの制作」) か、またはデータ ファイルを直接コピーする (項5.1.1.6. 「生データ ファイルでデータ スナップショットの作成」)。Master のセッティングでスレーブを設定する。例:ホスト名、ログイン認証、バイナリ ログ名、位置など。項5.1.1.10. 「マスタ コンフィギュレーションのスレーブでの設定」 を参照。
ここまでの基本的なオプションを設定後、次に示すレプリケーション セットアップの手順に従います。これにはいくつかの方法があります。
新たな MySQL マスタおよび複数のスレーブをセットアップする場合、交換するデータがまだ存在しないということから、コンフィギュレーションをセットアップする必要がある。この状況でのレプリケーション セットアップのガイドは 項5.1.1.7. 「新たなマスタとスレーブのレプリケーション セットアップ」 を参照。
MySQL サーバがすでに稼動している場合、つまりレプリケーションを開始する前にスレーブにデータを転送する必要があり、バイナリ ログ構成をしていない状況下で、処理中に短時間 MySQL サーバをシャットダウンできるときは、項5.1.1.8. 「既存データでのレプリケーション セットアップ」 を参照。
既存のレプリケーション環境で、追加サーバをセットアップ、そしてマスタに影響することなくスレーブをセットアップできる場合は、項5.1.1.9. 「既存のレプリケーション環境へのスレーブ追加」 を参照。
MySQL レプリケーション セットアップの管理者は、この節を十分に読み、項12.6.1. 「マスタ サーバをコントロールする SQL ステートメント」 および 項12.6.2. 「スレーブ サーバをコントロールする SQL ステートメント」 のすべてのステートメントを試行してください。項5.1.3. 「レプリケーションのオプションと変数」 に示すレプリケーションのスタートアップ オプションに関しても十分な理解が必要です。
注意
ノートとして、セットアップ
プロセス中の特定のステップで、SUPER
権限を必要とします。この権限がない場合は、レプリケーションはできません。
それぞれの Slave
は、通常のユーザ名とパスワードで Master
と接続する必要があります。このオペレーションに使用するこのユーザは、REPLICATION
SLAVE 権限を持つユーザのことです。
レプリケーションのために特定のユーザを作成する必要はありませんが、ユーザ名とパスワードは
master.info ファイル内のテキスト
ファイルに保存されるため、レプリケーション
プロセスにだけ権限があるユーザを作成するということです。
レプリケーションに必要な権限をユーザまたは既存のユーザに与えるには、GRANT
ステートメントを使用します。レプリケーションのためだけにユーザを作成する場合は、そのユーザは
REPLICATION SLAVE
権限だけを必要とします。たとえば、ユーザ作成時に、ドメイン
mydomain.com
内のすべてのホストにレプリケーション接続を許可するには、repl
を使用します。
mysql> GRANT REPLICATION SLAVE ON *.*
-> TO 'repl'@'%.mydomain.com' IDENTIFIED BY 'slavepass';
GRANT
スレートメントに関しては、項12.5.1.3. 「GRANT 構文」
を参照してください。
スレーブ毎のユーザを作成する場合、または接続時にそれぞれのスレーブに同一のユーザを使う場合に、レプリケーション
プロセスに使用するそれぞれのユーザに
REPLICATION SLAVE
権限があるという前提であれば、必要に応じてユーザ作成ができます。
レプリケーションを成功させるには、必ず マスタのバイナリ ロギングを実行可能にしてください。バイナリ ロギングの実行できないということは、マスタとスレーブの間でデータ交換に使うバイナリ ログがないということになり、レプリケーションは不可能です。
レプリケーション
グループのそれぞれのサーバには、ユニークな
server-id が必要です。この server-id
はそれぞれのサーバを識別するために使うため、1
から (232)-1)
間の正整数を使用します。採番方法は自由です。
これらのオプションを設定するには、MySQL
サーバをシャットダウンし、my.cnf
あるいはmy.ini
ファイルのコンフィギュレーションを編集します。
[mysqld]
セクション内のコンフィギュレーション
フィアルに次のルールを付加します。これらのルールがすでに存在し、コメント
アウトしている場合は、そのルールを非コメント化し、必要に応じて書き換えます。
[mysqld] log-bin=mysql-bin server-id=1
注意
ノート: トランザクションで
InnoDB
を使用したレプリケーションに、できる限りの耐用性と一貫性を期待する場合は、マスタの
my.cnf ファイルの
sync_binlog=1 と
innodb_flush_log_at_trx_commit=1
を使用します。
注意
skip-networking
ルールがレプリケーション
マスタで無効であることを確認してください。ネットワークが使用不可の場合は、スレーブはマスタとの通信ができないため、レプリケーションは成功しません。
スレーブで唯一設定しなければならないオプションは、ユニーク サーバ IDの設定です。このオプションを設定していない場合、またはマスタ サーバに指定した値と実行値が干渉する場合、スレーブ サーバをシャットダウンし、サーバ ID を指定するためにコンフィギュレーションを編集します。たとえば次のようにします。
[mysqld] server-id=2
複数のスレーブをセットアップする場合、それぞれにユニークな
server-id
値を与えます。この値はマスタおよびその他のスレーブとは異なる必要があります。server-id
値は、IP
アドレスのようなものと考えます。これらの ID
はコミュニティ内のレプリケーション
パートナー間で、それぞれのサーバ
インスタンスを一意的に識別します。
server-id
値を指定しない場合、master-host
を定義していなければ、この値は 1
です。それ以外は、 2
で設定します。server-id の省略
する場合は、マスタがすべてのスレーブからの接続を拒否し、スレーブはマスタへの接続を拒否します。そのため、server-id
を省略することは、バイナリ
ログでのバックアップにのみ有効といえます。
レプリケーション用にスレーブのバイナリ ロギングを可能にする必要はありません。しかし、スレーブのバイナリ ロギングを可能にすると、データ バックアップとクラッシュ リカバリにバイナリ ログを使用でき、スレーブを接続形態が複雑なレプリケーションに使用できます。
スレーブのレプリケーションを設定するには、マスタのバイナリ ログ内でマスタの現在位置を特定する必要があります。この情報は、スレーブがレプリケーション プロセスを開始するときに必要とします。それにより、正確な位置でバイナリ ログからのイベントを開始できます。
マスタに既存のデータがあり、それをレプリケーション プロセスを開始する前にスレーブと同期化するには、マスタのステートメント処理を停止し、現在位置を取得して、マスタにステートメント実行の継続を許可する前に、そのデータをダンプします。もし、ステートメントの実行を停止しないでデータのダンプを行うと、マスタのステータス情報に不一致が生じ、スレーブのデータベースが破損します。
マスタのステータス情報は、次のステップに従い取得します。
コマンド ライン クライアントを開始し、すべてのデータをフラッシュし、
FLUSH TABLES WITH READ LOCKステートメントを実行して書き込みステートメントをブロックする。mysql> FLUSH TABLES WITH READ LOCK;
このとき大切なこととして、
InnoDBテーブルでは、FLUSH TABLES WITH READ LOCKが、COMMITオペレーションもブロックすることに留意してください。警告
注意: 実行中の
FLUSH TABLESコマンドからクライアントを切り離します。読み込みブロックはそのまま有効です。クライアントを終了すると、このブロックはリリースされます。SHOW MASTER STATUSステートメントを使用して、現在のバイナリ ログ名を指定し、マスタとオフセットする。mysql >
SHOW MASTER STATUS;+---------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +---------------+----------+--------------+------------------+ | mysql-bin.003 | 73 | test | manual,mysql | +---------------+----------+--------------+------------------+Fileカラムはログの名前を示し、Positionはファイル内のオフセットを示します。この例では、バイナリ ログ ファイルはmysql-bin.003で、オフセットは 73 です。これらの値は、後でスレーブをセットアップするときに必要になるので、書き控えます。マスタからの新たなアップデートを処理するスレーブのレプリケーション座標です。バイナリ ロギングを行わない状態で、マスタが稼動していた場合、ログ名と位置の値は
SHOW MASTER STATUSに示されるか、または mysqldump --master-data は空の状態です。この場合、後でスレーブのログ ファイルと位置を指定するときの値は 空文字列 ('') および4です。
ここで、バイナリ ログからの読み込みを開始し、正確な位置からレプリケーションを行う準備がスレーブにできます。
レプリケーションを開始する前に、スレーブと同期化する必要がある既存データがある場合、クライアントをそのまま稼動させます。これによりロックは正しい位置に留まり、項5.1.1.5. 「mysqldump を使用したデータ
スナップショットの制作」
または 項5.1.1.6. 「生データ ファイルでデータ スナップショットの作成」
へ進みます。
新たにマスタとスレーブのレプリケーション グループをセットアップする場合には、クライアントを終了し、ロックをリリースします。
既存のマスタ
データベースでデータのスナップショットを作成する方法の一つに、mysqldump
ツールを使うことがあります。データのダンプが完了したら、レプリケーション
プロセスを開始する前に、そのデータをスレーブにインポートします。
mysqldump
を使用してデータのスナップショットを取得する方法
データを更新するクエリの実行を防ぐために、サーバのテーブルをまだロックしていない場合
コマンド ライン クライアントを開始し、すべてのデータをフラッシュし、
FLUSH TABLES WITH READ LOCKステートメントを実行して書き込みステートメントをブロックする。mysql> FLUSH TABLES WITH READ LOCK;
注意:
SHOW MASTER STATUSを使用し、スレーブをスタートアップするときに使うバイナリ ログの詳細を記録してください。このときのスナップショットとバイナリ ログの位置は一致する必要があります。詳細は、項5.1.1.4. 「マスタ レプリケーション情報の取得」 を参照。別のセッションでは、
mysqldumpを使用して、データベースすべて、または複製する分、あるいは個別に特定のデータベースを選択して、ダンプを作成する。shell> mysqldump --all-databases --lock-all-tables >dbdump.db
ベア ダンプの別方法としては、
--master-dataオプションを使用し、自動的に スレーブでのレプリケーション プロセスに必要なCHANGE MASTERステートメントを付加する。shell> mysqldump --all-databases --master-data >dbdump.db
ダンプを含むデータベースを選択する場合は、レプリケーション プロセスには不要なスレーブのデータベースにフィルタをかける必要があります。
データをインポートするときに、スレーブへ遠隔的に接続する場合は、ダンプ ファイルをスレーブにコピーするか、またはマスタからのファイルを使用します。
データベースが特段に大きい場合は、mysqldump
を使用してそれぞれのスレーブにファイルをインポートするよりも、生データ
ファイルをコピーする方が効率的な場合があります。
しかし、複雑なキャッシュやロギング アルゴリズムを使用しているストレージ エンジンのテーブルにこの方法を使うことは、完全にイン タイムのスナップショットにならない可能性があり、キャッシュ情報とロギング アップデートは、グローバル 読み込みロックを使っていたとしても、適用されない場合があります。これにストレージ エンジンがどのように反応するかは、クラッシュ リカバリ能力に依存します。
たとえば、グローバル
読み込みロックを使用していた場合、InnoDB
テーブルのファイルシステム
スナップショットを開始できます。内部的
(InnoDB ストレージ エンジンの中)
には、InnoDB
キャッシュをフラッシュしていないなどの理由で、スナップショットが乱れます。しかし、これはスタートアップ時に
InnoDB
によって解決され、一貫した結果が運ばれるため、問題になることはありません。つまり、InnoDB
は破損を伴わずに、クラッシュ
リカバリを行うことができる、ということですが、しかし、これは、
InnoDB
テーブルの一貫したスナップショットを確保する一方で、MySQLサーバをストップすることができないということです。
生データのスナップショットを作成するには、cp
または copy などの標準のコピー
ツール、scp or rsync
などの リモート コピー
ツール、zip or tar
などのアーカイブ ツール、dump
などのファイル システム スナップショット
ツールなどを使用し、MySQL データ
ファイルが単一のファイルシステムに存在すると定めます。特定のデータベースを複製するだけである場合は、テーブルに関係のあるファイルのコピーを取るだけであることを確認します。InnoDB
で、innodb_file_per_table
オプションを利用しない場合は、すべてのデータベースにあるすべてのテーブルを一つのファイルに格納します。
アーカイブから次のファイルを指定して取り除く場合
mysqlデータベースに関連するファイルmaster.infoファイルマスタのバイナリ ログ ファイル
リレー ログ ファイル
生データのスナップショットで最も一貫した結果を得るには、次の通りにプロセス中にサーバをシャットダウンします。
読み込みロック、マスタ ステータスを取得する。項5.1.1.4. 「マスタ レプリケーション情報の取得」 参照。
別のセッションで、MySQL サーバをシャットダウンする。
shell> mysqladmin shutdown
MySQL データ ファイルのコピーを取る。一般的なソリューションは次の例示の通り。この中から一つだけを選択する。
shell> tar cf
/tmp/db.tar./datashell> zip -r/tmp/db.zip./datashell> rsync --recursive./data/tmp/dbdataマスタの MySQL インスタンスを立ち上げる。
データベースをシャットダウンしないで、マスタからスナップショットを得る。
読み込みロック、マスタ ステータスを取得する。項5.1.1.4. 「マスタ レプリケーション情報の取得」 参照。
MySQL データ ファイルのコピーを取る。一般的なソリューションは次の例示の通り。この中から一つだけを選択する。
shell> tar cf
/tmp/db.tar./datashell> zip -r/tmp/db.zip./datashell> rsync --recursive./data/tmp/dbdataInnoDBテーブルを使用している場合、InnoDBHot Backup ツールの使用をお勧めします。これは、マスタ サーバのロックを取らずに一貫したスナップショットを取り、後にスレーブで使用するスナップショットに関連するログ名とオフセットを記録します。Hot Backup は業務用ツールであるため、標準の MySQL には含まれていません。詳細は、http://www.innodb.com/manual.php で、InnoDBHot Backupを参照してください。読み込みロックを取得したクライアントでは、ロックを解除する。
mysql> UNLOCK TABLES;
データベースのアーカイブまたはコピーを作成した後は、スレーブでレプリケーション プロセスを開始する前に、それぞれのスレーブにファイルをコピーします。
既存データがない場合などで、レプリケーションをセットアップする最も簡単な正攻法は、新たな Master と Slaves でセットアップすることです。
この方法は、新しいサーバをセットアップする場合に、レプリケーションのコンフィギュレーションにロードしたいデータベースの既存ダンプがあるときにも有効です。新しいマスタにデータをロードすると、データは自動的にサーバへ複製されます。
新しいマスタとスレーブでレプリケーションをセットアップする方法
必要なコンフィギュレーション属性で MySQL マスタを設定する。 項5.1.1.2. 「レプリケーション マスタのコンフィギュレーション設定」 を参照。
MySQL マスタを起動する。
ユーザをセットアップする。 項5.1.1.1. 「レプリケーション ユーザの作成」 を参照。
マスタのステータス情報を取得する。項5.1.1.4. 「マスタ レプリケーション情報の取得」 を参照。
読み込みロックを解除する。
mysql> UNLOCK TABLES;
スレーブで、MySQL コンフィギュレーションを編集する。 項5.1.1.3. 「レプリケーション スレーブのコンフィギュレーション設定」 を参照。
MySQL スレーブを起動する。
CHANGE MASTERコマンドを実行し、 マスタ レプリケーション サーバのコンフィギュレーションを設定する。
ロードまたは交換するデータが新しいサーバのコンフィギュレーションにないため、情報をコピーまたはインポートする必要はありません。
既存のデータベース サーバからのデータを使用して、新たなレプリケーション環境をセットアップする場合は、ここでマスタでダンプ ファイルを実行します。データベースの更新は自動的にスレーブへ伝播されます。
shell> mysql -h master < fulldb.dump
既存データでレプリケーションをセットアップするとき、レプリケーションを開始する前に、マスタからスレーブへの最も適当なデータ取得方法を検討します。
既存データでの基本的なレプリケーション セットアップ プロセスは次の通り。
server-idとバイナリ ロギングの設定をまだ行っていない場合、これらのオプションを設定するためにマスタをシャットダウンする。項5.1.1.2. 「レプリケーション マスタのコンフィギュレーション設定」 を参照。マスタのデータベースをシャットダウンする必要があるということは、データベースのスナップショットを取る良い機会です。データベースの取り出し、コンフィギュレーションの更新、スナップショット取得などの前に、まず、マスタ ステータスを取得します。(項5.1.1.4. 「マスタ レプリケーション情報の取得」 参照。) 生データ ファイルを使用したスナップショットの作成に関しては 項5.1.1.6. 「生データ ファイルでデータ スナップショットの作成」 を参照してください。
サーバがすでに正確に設定されている場合は、マスタ ステータスを取得し (項5.1.1.4. 「マスタ レプリケーション情報の取得」 参照)、
mysqldumpを使用してスナップショットを取る (項5.1.1.5. 「mysqldumpを使用したデータ スナップショットの制作」 参照)、または 項5.1.1.6. 「生データ ファイルでデータ スナップショットの作成」 のガイドを使用してライブ データベースの生スナップショットを取る。MySQL マスタが稼動している状態で、レプリケーション中にスレーブがマスタへ接続するときに使うユーザを作成する。項5.1.1.1. 「レプリケーション ユーザの作成」 参照。
スレーブのコンフィギュレーションを更新する。項5.1.1.3. 「レプリケーション スレーブのコンフィギュレーション設定」 参照。
マスタにあるデータのスナップショットをどのように取るかによって、次のステップは異なります。
mysqldump を使用した場合
--skip-slaveオプションを使用してレプリケーションをスキップし、スレーブを立ち上げる。ダンプ ファイルをインポートする。
shell> mysql < fulldb.dump
生データ ファイルでスナップショットを作成した場合
スレーブのデータ ディレクトリにデータ ファイルを展開する。
shell> tar xvf dbdump.tar
ノート:スレーブのコンフィギュレーションと一致するようにファイルの権限と所有権の設定が必要な場合があります。
--skip-slaveオプションを使用してレプリケーションをスキップし、スレーブを立ち上げる。
マスタ ステータス情報でスレーブを設定します。これにより、レプリケーションを開始するために必要なバイナリ ログ ファイルと位置 (ファイル内) を伝え、ログイン認証とマスタのホスト名を設定します。ここで必要なステートメントに関する詳細は、項5.1.1.10. 「マスタ コンフィギュレーションのスレーブでの設定」 を参照してください。
スレーブ スレッドを立ち上げる。
mysql>
START SLAVE;
この手順を行った後、スレーブはマスタに接続し、最後にスナップショットからのアップデートにキャッチアップします。
マスタに server-id
オプションの設定をしていなかった場合、スレーブは接続できません。
スレーブに server-id
オプションを設定していなかった場合、スレーブのエラー
ログに次にようなエラーが示されます。
Warning: You should set server-id to a non-0 value if master_host is set; we will force server id to 2, but this MySQL server will not act as a slave.
何らかの理由で、複製ができない場合は、スレーブのエラー ログにエラー メッセージがあります。
スレーブでの複製開始後、そのデータ
ディレクトリに master.info と
relay-log.info
という名前のファイルをそれぞれ見つけることができます。スレーブはこれら
2 つのファイルからマスタのバイナリ
ログでどれくらい処理されたかを読み取ります。そのため、動作への影響に関して完全に理解している場合を除いて、これらのファイルは決して削除または編集
しないで
ください。その必要がある場合は、CHANGE
MASTER TO
ステートメントを使用して、レプリケーションのパラメータを変更することをお勧めします。スレーブは、ステートメントで指定した値に従い自動的にステータス
ファイルを更新します。
注意
master.info
の内容は、コマンドラインまたは
my.cnf などで指定したサーバ
オプションの一部を優先します。詳細は
項5.1.3. 「レプリケーションのオプションと変数」
を参照してください。
マスタのスナップショットの準備が整ったら、上記に示したスレーブ部分の手順に従って、別のスレーブのセットアップにそれを使用します。マスタから新たに別のスナップショットを作成する必要はありません。それぞれのスレーブに同一のスナップショットを使用できます。
既存のレプリケーション コンフィギュレーションにスレーブを追加する場合には、マスタを止める必要はありません。スレーブ (複数) のセッティングを複製します。
スレーブを複製する方法
既存スレーブをシャットダウンする (Slave A)
shell> mysqladmin shutdown
既存スレーブから新スレーブにデータ ディレクトリをコピーする。これは、tar または
WinZipなどの使用したアーカイブを作成するか、もしくは cp または rsync などのツールを使用して直コピーを実行するかのどちらかで行う。さらに、ログ ファイルやリレー ログ ファイルをコピーしておく。master.infoまたはrelay.infoファイルを既存スレーブからコピーする。これらのファイルはその段階でのログ位置を保持している。既存スレーブを起動する。
新スレーブでは、コンフィギュレーションを編集し、新スレーブに新ユニーク
server-idを与える。新スレーブを起動する。
master.infoファイルのルールでレプリケーション プロセスが開始される。.
レプリケーションで、スレーブをマスタと通信するようセットアップするには、スレーブに必要な接続情報を伝える必要があります。それには、次のステートメントをスレーブで実行して、オプション値をシステムに合わせた実際の値と置き換えます。
mysql>CHANGE MASTER TO->MASTER_HOST='->master_host_name',MASTER_USER='->replication_user_name',MASTER_PASSWORD='->replication_password',MASTER_LOG_FILE='->recorded_log_file_name',MASTER_LOG_POS=recorded_log_position;
次のテーブルは文字列値オプションの最大許容長さを示します。
MASTER_HOST | 60 |
MASTER_USER | 16 |
MASTER_PASSWORD | 32 |
MASTER_LOG_FILE | 255 |
バイナリ ログに書き込まれたイベントをマスタが読み込み、スレーブで処理することでレプリケーションが成り立ちます。このイベントは記録されるイベントに従って様々なフォーマットで記録されます。このフォーマットは次の通りです。
MySQL のレプリケーション能力は、 マスタからスレーブへの SQL ステートメントの伝播に基づいています。これをステートメント ベース レプリケーション (SBR) と呼びます。
行ベースのレプリケーション (RBR) では、マスタがイベントをバイナリ ログに書き込み、ログは個々のテーブル行がどのように影響を受けたかを示します。MySQL 5.1.5 で追加された RBR に関するサポートは を参照してください。
MySQL 5.1.8 より、第 3 のオプションが利用可能になりました。ミックス ベース レプリケーション (MBR) です。MBR では、デフォルトでステートメント ベース レプリケーションが行われますが、自動的に行ベース レプリケーションに切り替わります。次のケースがそれに該当します。項5.1.2.2. 「ミックス レプリケーション フォーマット」 も参照してください。
MySQL 5.1.12 から、ミックス ベース レプリケーション (MBR) がデフォルト フォーマットで、指定のない限り、すべてのレプリケーション環境に対応します。
ステートメント ベースと行ベースのレプリケーション比較で、それぞれのメリット、デメリットを確認できます。詳細は 項5.1.2.3. 「ステートメント ベースと行ベースのレプリケーション比較」 を参照してください。
MySQL クラスタ レプリケーション (MySQL Cluster Replication) は行ベース レプリケーションに最適です。詳細は 項14.10. 「MySQL Cluster レプリケーション」 を参照してください。
MySQL の典型的なステートメント ベース レプリケーションには、格納ルーチンやトリガを複製するときに問題が生じる可能性があります。これらの問題は、MySQL の行ベース レプリケーションを代用して回避できます。問題に関する詳細は 項17.4. 「ストアドルーチンとトリガのバイナリログ」 を参照してください。
MySQL をソースから構築した場合、
--without-row-based-replication
オプションで configure を
呼び出さない限り、行ベース
レプリケーションはデフォルトで使用できます。
デフォルトのレプリケーション フォーマットは、使用している MySQL のバージョンによって異なります。
MySQL 5.1.11 以前の場合は、ステートメント ベース レプリケーションがデフォルトです。
MySQL 5.1.12 以降の場合は、ミックス ベース レプリケーションがデフォルトです。
--binlog-format=
オプションにフォーマットを指定すると、デフォルトのレプリケーション
フォーマットを強制できます。その場合、サーバに接続しているすべてのレプリケーション
スレーブは、そのセッティングに従ってイベントを読み込みます。サポートされているオプションは次の通りです。
type
ROW? は行ベース レプリケーションをデフォルトに設定。STATEMENT? はステートメント ベース レプリケーションをデフォルトに設定。 MySQL 5.1.11 以前のフォーマット。MIXED? はミックス ベース レプリケーションをデフォルトに設定。 MySQL 5.1.12 以降のフォーマット。
ロギング
フォーマットはランタイムでも変更できます。すべてのクライアントに対して、グローバル
フォーマットを指定するには、binlog_format
システム変数のグローバル値を設定します。グローバル変数を変更するには、SUPER
権限が必要です。
ステートメント ベース フォーマットに切り替えるには、次のステートメントのどれかを使用します。
mysql>SET GLOBAL binlog_format = 'STATEMENT';mysql>SET GLOBAL binlog_format = 1;
行ベース フォーマットに切り替えるには、次のステートメントのどれかを使用します。
mysql>SET GLOBAL binlog_format = 'ROW';mysql>SET GLOBAL binlog_format = 2;
ミックス ベース フォーマットに切り替えるには、次のステートメントのどれかを使用します。
mysql>SET GLOBAL binlog_format = 'MIXED';mysql>SET GLOBAL binlog_format = 3;
それぞれのクライアントは、それぞれのステートメントのロギング
フォーマットをコントロールできます。それには、binlog_format
のセッション値を設定します。次はその例です。
mysql>SET SESSION binlog_format = 'STATEMENT';mysql>SET SESSION binlog_format = 'ROW';mysql>SET SESSION binlog_format = 'MIXED';
ロギング
フォーマットの手動による切り替えのほかに、スレーブ
サーバが 自動的に
そのフォーマットを変更する場合もあります。これは、サーバが
STATEMENT または MIXED
のフォーマットのどちらかで実行てているときに生じ、ROW
ロギング フォーマットでバイナリ
ログの書き込みをしている行と衝突します。この場合、スレーブは一時的にそのイベントに合わせて行ベース レプリケーションに移行し、その後は元のフォーマットに戻ります。
接続毎でのレプリケーション ロギングの設定には、2 つの検討事項があります。
データベースに多少の変更を加えるスレッドには、行ベース ロギングが妥当である。
WHERE節に一致するアップデートを行うスレッドには、数の多い行をログするよりもステートメントでの方が効率的であるためステートメント ベース ロギングが妥当である。マスタにおいて多くの実行を必要とするステートメントがあり、それによる修正行が少ない場合、それらを行ベース ロギングで複製する方が有益である。
ランタイムでレプリケーション フォーマットを切り替えることができない場合があります。
格納関数またはトリガ内からの場合
NDBが有効な場合セッションが行ベース レプリケーション モードであり、一時テーブルを開いている場合
これらのケースでフォーマットを変更すると、エラーになります。
一時テーブル
が存在する場合に、ランタイムでのレプリケーション
フォーマットの切り替えることはしないでください。ステートメント
ベース
レプリケーションを使用しているときにだけ一時テーブルはログでき、行ベース
レプリケーションの場合にはログできません。ミックス
レプリケーションの場合は、一時テーブルはログできますが、ユーザ定義関数
(UDF) および UUID()
関数を使用している場合はこの限りではありません。
ROW にセットした binlog
フォーマットでは、行ベースのフォーマットを使用してバイナリ
ログに多くの変更が書き込まれます。しかし、変更の一部はステートメント
ベース
フォーマットである場合があります。たとえば、CREATE
TABLE、ALTER TABLE、DROP
TABLE など DLL (データ定義言語)
ステートメントを含む場合がこれに該当します。
--binlog-row-event-max-size
オプションは行ベース
レプリケーションができるサーバで使用できます。行はオプション値を越えないバイト
サイズを一塊としてバイナリ
ログに格納されます。この値は 256
の倍数です。デフォルト値は 1024 です。
警告
データ修正が non-deterministic であるようにステートメントがデザインされていた場合、行ベース レプリケーション を使用するとき、マスタとスレーブにあるデータをそれぞれ異なるものにすることができます。つまり、クエリ オプティマイザの意向次第ということです。レプリケーション以外の目的で、これを行うこは一般的ではありません。詳細は、項B.1.8.1. 「Open Issues in MySQL」 を参照してください。
MIXED
モードで実行している場合、次の条件下にあるレプリケーションはステートメント
ベースから行ベースに自動的に切り替わります。
DML ステートメントが
NDBテーブルを更新するとき関数に
UUID()が含まれているときAUTO_INCREMENTカラムを伴う 2 つ以上のテーブルを更新するときINSERT DELAYEDを実行するときビュー ボディが行ベース レプリケーションを要求し、そのビューを作成しているステートメントがそれを使用するとき ? たとえば、ビューを作成しているステートメントが
UUID()関数を使用するときUDF の呼び出しに関わるとき
バイナリ ロギングのフォーマットにはそれぞれ、メリットとデメリットがあります。大抵の場合、ミックス ベース レプリケーションのフォーマットで対応でき、データの整合性とパフォーマンスにおいては最適なコンビネーションです。しかし、特定のアップデートや大量データの挿入などを行うときに、レプリケーション フォーマットの違いをメリットとして扱う場合などがあります。そのため、この章では、行ベースとステートメント ベースのそれぞれのフォーマットにおけるメリットとデメリットを概説します。
ステートメント ベース レプリケーションのメリット
バージョン 3.23 以来、MySQLに存在する実証済みテクノロジー
ログ ファイルが小さい。更新や削除が数多くの行に影響する場合は、ログ ファイルが 一段と 小さくなる。少量ログ ファイルはストレージ スペースを節約でき、バックアップも早くできる。
ログ ファイルには変更があったすべてのステートメントが含まれるため、データベースの監査に使える。
ログ ファイルはポイント イン タイムのリカバリなど、レプリケーション目的以外にも使える。項4.9.3. 「任意時点のリカバリ」 参照。
テーブルの行ストラクチャが異なる場合でも、マスタで使っているものよりも新しいバージョンを使用しているスレーブを使用できる。これはマスタのアップグレードはできないが、スレーブの最新バージョンに備わっている機能を活用できるなどの有用性がある。これは、テストや評価などの目的としても有効である。
ステートメント ベース レプリケーションのデメリット
UPDATEステートメントのすべてを複製することができない。非決定性の動作 (例:SQL ステートメントのランダム関数使用時など) は、ステートメント ベース レプリケーションを使用している場合は複製が困難である。非決定性のユーザ定義関数 (UDF) を使用したステートメントの場合、行ベース レプリケーションでは UDF の戻り値を複製するだけであることに対して、ステートメント ベース レプリケーションでの結果は複製することができない。非決定性の UDF を使用している場合に、ステートメントが適切に複製されない。(値が与えられたパラメータよりも別のファクタに依存する。)
次の関数を使用するステートメントは正確な複製にならない。
LOAD_FILE()UUID()USER()FOUND_ROWS()SYSDATE()(--sysdate-is-nowオプションでサーバを起動した場合を除く)
これ以外の関数での複製は正確である。 (
RAND()、NOW()、LOAD DATA INFILEなど)INSERT ... SELECTは、行ベース レプリケーションのときよりも、行レベルのロック数をより必要とする。(
WHERE節でインデックスを使用していないなどの理由で、テーブル スキャンを必要とするUPDATEステートメントは、行ベース レプリケーションのときよりも行数をより多くロックしなければならない。InnoDBの場合、AUTO_INCREMENTを使用するINSERTステートメントは、干渉しないINSERTステートメントなどもブロックする。.複雑なクエリの場合、ステートメントの評価および行の更新または挿入を行う前にスレーブで実行する必要がある。行ベース レプリケーションでは、スレーブはクエリ全体ではなく、部分的に違いを適用するためだけに、スレートメントを実行する。
格納機能 (格納プロシージャではない) を呼び出しステートメントと同一の
NOW()値で実行する。(これには良し悪しがある)決定性のある UDF をスレーブに適用しなければならない。
スレーブでの評価にエラーがあった場合、特に複雑なクエリを実行しているときには、ステートメント ベース レプリケーションでは、行への影響があるエラーのマージンが時間をかけてゆっくり増加することがある。
マスタとスレーブは殆ど同一でなければならない。
行 ベース レプリケーションのメリット
すべて複製できる。最も安全なレプリケーションの形式である。
5.1.14 以前のバージョンの MySQL では、
CREATE TABLEのような DDL (データ定義言語) ステートメントはステートメント ベース レプリケーションを使用して複製します。一方の DML (Data Manipulation Language) ステートメントの場合は、GRANTやREVOKEステートメントと同様に行ベース レプリケーションを使用した複製です。MySQL 5.1.14 以降では、
mysqlデータベースは複製されません。mysqlデータベースはノード指定型データベースとして考えます。行ベース レプリケーションはこのテーブルをサポートしません。その代わりに、GRANTやREVOKEといった通常、情報を更新するステートメント、操作トリガ、格納ルーチン/プロシージャ、そしてビューなどすべてをステートメント ベース レプリケーションでスレーブへ複製します。CREATE ... SELECTのようなステートメントの場合は、CREATEステートメントがテーブル定義から生成され、ステートメント ベースの複製、一方、行挿入は行ベースです。このテクノロジーは他のデータベース管理システムとほぼ同じで、別システムに関する知識は MySQL でも使える。
多くの場合、主キーを保持しているテーブルにはスレーブにデータを適用する方が速い。
次のタイプのステートメントでは、マスタのロック数が少ない (高い同時並行性) 。
INSERT ... SELECTAUTO_INCREMENTでINSERTステートメントキーを使用しない、またはチェック済み行の殆どを変更しない。
WHERE節でUPDATEまたはDELETEステートメント。
INSERT、UPDATE、DELETEステートメント へのスレーブのロック数が少ない。将来的に、データをスレーブに適用する複数のスレッドを加えることができる。(SMP マシンとの相性が良い)
行 ベース レプリケーションのデメリット
ログ ファイルが大きい (ケースによってはかなり大きい)
バイナリ ログにはロールバックした大きなステートメントが含まれる。
ステートメントを複製するために、行ベース レプリケーションを使用するときに (例:
UPDATEまたはDELETEなど)、変更された行のそれぞれがバイナリ ログに書き込まれなければならない。一方では、ステートメント ベース レプリケーションを使用する場合は、そのステートメントだけがバイナリ ログに書き込まれる、ステートメントが多くの行を変更する場合、行ベース レプリケーションはバイナリ ログのより多くのデータを書き込む可能性がある。これらのケースでは、バイナリ ログはデータを書き込むために長時間ロックされ、これは、同時並行性の問題を偶発する。大きな
BLOB値を生成する決定性 UDF は複製速度を著しく低下させる。どのステートメントが実行できたかを調べるためにログをチェックすることができない。
スレーブがマスタからどのステートメントを受信し、実行したかを知ることができない。
非トランザクション ストレージ エンジンを含め、バルク オペレーションを行う場合、変更はステートメントが実行するものとして適用される。これは、行ベース レプリケーション ロギングの場合、バイナリ ログがステートメント実行中に書き込まれることを示す。一方、マスタでは、テーブルはバルク オペレーションが済むまでロックされているため、これが同時並行性に影響を与えることはない。しかし、スレーブ サーバでは、これらの変更はバルク オペレーションの一部ということを認識しないため、スレーブが変更を適用している間にテーブルがロックされない。
このシナリオでは、
SELECT * FROM table_nameなどで、マスタのテーブルからデータを取り戻す場合に、サーバはSELECTステートメントを実行する前に、バルク オペレーションの完了を待機します。これは読み込むテーブルがロックされているためです。スレーブでは、ロックされていないため、サーバは待機しません。これは、 スレーブ’での 「バルク オペレーション」 が完了するまで、同一のSELECTクエリから異なる結果がマスタとスレーブに生じるということです。この動作は、最終的に変更しますが、それが実現するまでは、このようなシナリオに至る可能性がある場合は、ステートメント ベース レプリケーションを行うことをお勧めします。
ここでは、スレーブ レプリケーション サーバに使用するオプションを説明します。これらのオプションはコマンド ラインまたはオプション ファイルで指定します。
マスタとスレーブ (複数)
では、server-id
オプションを使用して、ユニークなレプリケーション
ID を設置します。それぞれのサーバには、 1 から
232 ? 1
までの範囲のユニークな正整数を使用します。それぞれの
ID は別の ID
と重複しないようにしてください。例:server-id=3
バイナリ ロギングをコントロールするためにマスタ サーバに使用できるオプションは 項4.11.4. 「バイナリ ログ」 を参照してください。
スレーブ サーバ レプリケーション
オプションのいくつかは、特別の方法で扱います。それぞれが無視される、という意味においては、スレーブの起動時に
master.info
ファイルが存在し、オプションの値を含む場合です。次のオプションはこのように扱います。
--master-host--master-user--master-password--master-port--master-connect-retry--master-ssl--master-ssl-ca--master-ssl-capath--master-ssl-cert--master-ssl-cipher--master-ssl-key
MySQL 5.1 の master.info
ファイル フォーマットには、SSL
オプションに対応する値を含みます。さらに、ファイルフォーマットは、その最初のラインとしてラインの数をファイルに含みます。(項5.5.5. 「レプリケーション リレーとステータス ファイル」
参照) 古いバージョン (MySQL 4.1.1以前)
から新しいバージョンにアップグレードする場合は、新しいサーバは
master.info
ファイルを新しいフォーマットへ起動とともに自動的にアップグレードします。しかし、新しいサーバを古いバージョンにダウングレード
(格下げ)
する場合には、古いサーバを起動させる前に、まず手動で最初のラインを取り除く必要があります。
master.info
ファイルが存在しない状態でスレーブ
サーバを起動する場合には、オプション
ファイルまたはコマンド
ラインで指定されたルールの値が適用されます。これは、一番最初にレプリケーション
スレーブとしてサーバを起動するとき、または
RESET SLAVE
の実行後にスレーブをシャットダウンし再起動した場合などに起こります。
master.info
ファイルがスレーブ起動時に存在する場合は、サーバはそのファイル内にあるものを使用し、ファイルにリストされた値に呼応するオプションを無視します。このため、master.info
の値に呼応するスタートアップ
オプションとは異なる値でスレーブ
サーバを起動する場合には、その異なる値が影響を与えることはありません。つまりサーバは
master.info
ファイルを使用し続けるということです。異なる値を使用するには、master.info
ファイルを取り除いてから再起動するか、または
CHANGE MASTER TO
ステートメントを使用して、スレーブ実行中に値をリセットすることをお勧めします。
my.cnf
ファイルで次のルールを指定したとします。
[mysqld]
master-host=some_host
レプリケーション
スレーブとして初めてサーバを起動するとき、そのサーバは
my.cnf
ファイルからのオプションを読み込み、使用します。そして、master.info
ファイルの値を記録します。そして、この次にサーバを起動するときには、master.info
ファイルからの値をマスタ
ホスト値として読み込み、オプション
ファイルの値は無視されます。my.cnf
ファイルを修正する場合に、some_other_host
で別のサーバ
ホストを指定するときには、この変更は反映されません。よって、CHANGE
MASTER TO を使用します。
サーバが、記述したばかりのスタートアップ
オプションよりも、既存 master.info
ファイルを優先するため、これらの値をスタートアップ
オプションに使用するよりも、CHANGE MASTER
TO
ステートメントを使用して値を指定する方が賢明です。詳細は、項12.6.2.1. 「CHANGE MASTER TO 構文」
を参照してください。
以下は、スレーブ サーバを設定するときのスタートアップ オプションを拡大的にしようした場合の例です。
[mysqld] server-id=2 master-host=db-master.mycompany.com master-port=3306 master-user=pertinax master-password=freitag master-connect-retry=60 report-host=db-slave.mycompany.com
次のリストは、レプリケーションをコントロールするオプションと変数について説明します。これらのオプションの多くは、CHANGE
MASTER TO
ステートメントを使用してサーバ実行中にリセットできます。しかし、--replicate-*
のようなオプションは、スレーブ
サーバが起動するときにだけセットできます。
スレーブは通常、マスタ サーバから受けるアップデートを自身のバイナリ ログに記録しない。つまり、スレーブの SQL スレッドで実行された更新を、スレーブのバイナリログに記録するようにスレーブに指示する。このオプションを有効にするには、バイナリログを有効にする
--log-binオプションを使用して、スレーブを起動する必要がある。レプリケーション サーバをチェーン状に構成するには、--log-slave-updatesを使用する。たとえば、次のようにレプリケーション サーバをセットアップできる。A -> B -> C
A はスレーブ B のマスタとして機能し、B はスレーブ C のマスタとして機能する。この構成では、B がマスタでもあり、スレーブでもある。 そのため、A と B は両方とも、
--log-binオプションでバイナリログを有効にして起動し、--log-slave-updatesオプションで B を起動する必要がある。これにより、Aから受けたアップデートは B のバイナリ ログに記録される。このオプションは、スレーブにより詳細なメッセージを出力させる。たとえば、ネットワークまたは接続が切断された後で再接続に成功したというメッセージや、それぞれのスレーブ スレッドがどのように開始したかについての情報メッセージを出力することができる。 このオプションはデフォルト設定。これを無効にするには、
--skip-log-warningsオプションを使用する。中断された接続は、その値が 1 を越えない限り、エラー ログには記録されない。--master-connect-retry=secondsマスタがダウンするか接続不可の場合にマスタへ再接続を試行する前に、スレーブ スレッドがスリープ状態になる秒数。
master.infoファイルの値が読み込れる場合、その値が優先される。設定しなければ、デフォルトで 60 秒。--slave-net-timeoutの値に基づくマスタからのデータ読み込みに対してタイムアウトするまで、スレーブによる再接続の自動呼び出しは行われない。再接続の試行の回数は、--master-retry-countで制限する。マスタ レプリケーション サーバのホスト名または IP アドレスを指定する。
master.infoの値を読み取れる場合は、ファイルで指定する値が優先になる。マスタ ホストを指定しない場合、スレーブ スレッドは開始されない。マスタの情報をスレーブが記録するファイルに使う名前。デフォルトの名前は
master.infoで、データ ディレクトリにある。マスタへの接続時に、スレーブスレッドが認証に使用するアカウントのパスワード。
master.infoの値を読み取れる場合は、この値が優先される。設定しなければ、空白パスワードと見なされる。マスタがリスニングするTCP/IP ポート番号。
master.infoの値を読み取れる場合、その値が優先される。 設定しなければ、コンパイルされた設定 (3306) が採用される。スレーブがギブアップするまで、マスタへの接続を試行する回数。再接続のインターバルは
--master-connect-retryで設定する。再接続のトリガは、--slave-net-timeoutオプションのスレーブのデータ読み込みのタイム アウトに基づく。デフォルト値は 86400。--master-ssl,--master-ssl-ca=,file_name--master-ssl-capath=,directory_name--master-ssl-cert=,file_name--master-ssl-cipher=,cipher_list--master-ssl-key=file_nameSSL を使用してマスタ サーバに接続する安全なレプリケーション接続のセットアップに使用するオプション。
--ssl、--ssl-ca、--ssl-capath、--ssl-cert、--ssl-cipher、--ssl-keyなどの意義は、項4.8.7.3. 「SSL コマンド オプション」 を参照する。master.infoファイルのをが読み取れる場合は、それが優先される。マスタへの接続時に、スレーブ スレッドが認証に使用するアカウントのユーザ名。アカウントには
REPLICATION SLAVE権限が必要。master.infoの値を読み取れる場合は、その値が優先される。 マスタ ユーザ名が設定されていない場合、名前はtestと想定する。サーバがリレー ログを自動的にローテートするサイズ。詳細は 項5.5.5. 「レプリケーション リレーとステータス ファイル」 を参照。
スレーブ スレッドまたは
SUPER権限を持つユーザ以外からはアップデートを受けないようにスレーブに設定。これで、スレーブ サーバがクライアントからのアップデートを受けないように設定できる。このオプションはTEMPORARYには適用されない。リレー ログの名前。デフォルトでは
host_name-relay-bin.nnnnnnhost_nameはスレーブ サーバ ホストの名前、nnnnnnはシーケンス番号でのリレー ログ。このオプションを指定して、ホスト名とは独立したリレー ログ名を作成できる。あるいは、リレー ログが大きくなり、max_relay_log_sizeを下げない場合は、データ ディレクトリとは別の場所に置く必要がある。またはディスク間の負荷バランスにあわせてスピードを上げる場合にも使用できる。リレー ログ インデックス ファイルに使用する名前。デフォルトでは
host_name-relay-bin.indexhost_nameはスレーブ サーバの名前。--relay-log-info-file=file_nameスレーブがリレー ログの情報を記録するファイルに使う名前。デフォルトの名前は
relay-log.infoで、データ ディレクトリにある。リレー ログ ファイルが不要になったときの自動パージを有効または無効にする。デフォルト値は 1 (=有効)。 これは、
SET GLOBAL relay_log_purge =で動的に変更できるグローバル変数である。Nこのオプションは、スレーブのすべてのリレー ログの合計サイズ条件 (上限) を設定する。値 0 は 「無制限'」という意味。スレーブ サーバ ホストのハードディスクに限りが場合に便利である。上限に達すると、SQL スレッドが、キャッチアップしてクエリを実行し終えて、不要になったリレー ログを削除するまで、I/O スレッドがマスタ サーバからのバイナリ ログ イベントの読み込みを一時的に停止する。注意:この上限は絶対的なものではない。SQL スレッドがリレー ログを削除するためにさらにイベントを必要とする場合があり、その場合は削除が可能になるまで、I/O スレッドは制限を超えて続行する。続行しなければデッドロックが発生する。
--relay-log-space-limitは、--max-relay-log-size値の 2 倍より小さく設定してはいけない。また、--max-relay-log-sizeが 0 の場合は--max-binlog-size値の 2 倍より小さく設定してはいけない。小さく設定した場合、--relay-log-space-limitが超過しているために I/O スレッドが待機している間、SQL スレッドにはパージできるリレーログがない。 そして、I/O スレッドは一時的に--relay-log-space-limitを無視することになる。デフォルトのデータベース
db_nameのステートメントにレプリケーションを制限するようスレーブに指示する。つまり、USEで選択したもの。一つ以上のデータベースを指定するには、このコマンドを数回使用する。これは、クロス データベース ステートメントの複製には使用しない。これは、別のデータベースを選択、あるいはデータベースを全く選択しない、UPDATEのようなものである。some_db.some_tableSET foo='bar'警告
複数のデータベースを指定するには、このオプションに複数のインスタンスを使う必要がある。データベース名にはカンマが含まれているため、カンマ区切りのリストの場合に、リストが単一のデータベースの名前として扱われます。
以下は、期待とは沿わない可能性がある事柄の一例です。
--replicate-do-db=salesオプションでスレーブを起動し、マスタに次のステートメントを発行するが、UPDATEステートメントが複製されない。USE prices; UPDATE sales.january SET amount=amount+1000;
「 デフォルト データベースをチェックするだけ」 という動作の主な理由は、ステートメントだけでは複製をするべきかどうかの判断が難しいということである。たとえば、複数テーブルの
DELETEステートメント、または複製テーブルのUPDATEステートメントの場合は、複数のデータベースに作用するこということである。さらに必要がない限り、すべてのデータベースよりも府デフォルト データベースだけをチェックする方が速いということである。クロス データベース アップデートを行うには、
--replicate-wild-do-table=を使用する方が好ましい。詳細は 項5.5.6. 「サーバのレプリケーション ルール評価」 を参照。db_name.%--replicate-do-table=db_name.tbl_name指定テーブルへのレプリケーションを限定するようスレーブスレッドに指示。一つ以上のテーブルを指定するには、これを数回使用する。これは、
--replicate-do-dbとは対照的に、クロス データベース アップデートに利用できる。詳細は 項5.5.6. 「サーバのレプリケーション ルール評価」 を参照。db_nameのデフォルト データベースである場合のステートメントを複製しないようスレーブに指示。このデータベースは、USEで選択したものである。無視するテーブルを一つ以上指定するには、このオプションを複数回使用する。クロス データベース アップデートを使用していて、そのアップデートを複製しない場合は、このオプションを使用しない。詳細は 項5.5.6. 「サーバのレプリケーション ルール評価」 を確認。以下は、期待とは沿わない可能性がある事柄の一例です。
--replicate-ignore-db=salesオプションでスレーブを起動し、マスタに次のステートメントを発行するが、UPDATEステートメントが複製される。USE prices; UPDATE sales.january SET amount=amount+1000;
注意
上記の例では、
--replicate-ignore-dbはデフォルト データベースだけに適用されるため、ステートメントの複製が行えます。(USEステートメントで設定。)salesデータベースはステートメントで明確に指定があったために、ステートメントはフィルタされない。クロス データベース アップデートを行うには、
--replicate-wild-ignore-table=を使用する方が好ましい。詳細は 項5.5.6. 「サーバのレプリケーション ルール評価」 を参照。db_name.%--replicate-ignore-table=db_name.tbl_name指定テーブルを更新するステートメントを複製しないようスレーブ スレッドに指示。同一のステートメントで別のテーブルが更新されている可能性がある場合でも。一つ以上のテーブルを指定するには、これを複数回、それぞれのテーブルに使用する。これは、
--replicate-ignore-dbとは対照的に、クロス データベース アップデートに利用できる。詳細は 項5.5.6. 「サーバのレプリケーション ルール評価」 を参照。--replicate-rewrite-db=from_name->to_nameデフォルト データベースを
to_nameにトランスレートするようスレーブに指示。このデータベースは、USEで選択したものであり、from_nameがマスタのものである場合である。テーブルに関わるステートメントだけに影響し (CREATE DATABASE、DROP DATABASE、ALTER DATABASEなどのステートメントは例外)、from_nameがマスタのデフォルト データベースである場合だけである。これはクロス データベース アップデートには利用できない。データベース名のトランスレーションは、--replicate-*ルールでテストする前に行う。このオプションをコマンド ラインに使用し、‘
>’ キャラクタがコマンドのインタープリタとして特別である場合は、オプション値を指定する。次はその例である。shell>
mysqld --replicate-rewrite-db="olddb->newdb"スレーブ サーバで使用する。循環レプリケーションによる無限ループを防ぐために、デフォルトでは 0 に設定されている。1 で設定する場合、スレーブは自身のサーバ ID を持つイベントをスキップしない。通常、これは特別なコンフィギュレーションでのみ有効である。
--log-slave-updatesを使用している場合は、1 を設定することはできない。デフォルトで、スレーブ I/O スレッドにスレーブ サーバの ID がある場合は、バイナリ ログにバイナリ ログ イベントを書き込まない。(スレーブ デスク使用量の最適化。) そのため、--replicate-same-server-idを使用する場合は、スレーブがスレーブ SQL スレッドで実行するイベントを自分のものとして読み取るようにする前に、このオプションでスレーブを起動する。--replicate-wild-do-table=db_name.tbl_nameスレーブ スレッドにステートメントへのレプリケーションを制限するよう指示。このステートメントは指定のデータベースとテーブル名パターンと一致するテーブルのアップデートのことである。パターンには ‘
%’ そして ‘_’ などのワイルドカード文字が含まれる。これは、LIKEパターン マッチング オペレータとして同一の意義を持つ。一つ以上のテーブルを指定するには。このオプションを複数回、それぞれのテーブルに使用する。クロス テーブル アップデートにも使用できる。詳細は項5.5.6. 「サーバのレプリケーション ルール評価」 を参照。例:
--replicate-wild-do-table=foo%.bar%はデータベース名がfooで、テーブル名がbarで、それぞれ始まるテーブルを使用しているアップデートだけを複製する。テーブル名のパターンが
%の場合、テーブル名と一致し、オプションはデータベース レベル ステートメントに適用する。(CREATE DATABASE、DROP DATABASE、ALTER DATABASE) たとえば、--replicate-wild-do-table=foo%.%オプションを使用する場合、データベース レベル ステートメントは、データベース名がfoo%のパーターンと一致する場合に複製する。リテラルのワイルドカード文字をデータベースまたはテーブル名パターンに含むには、バックスラッシュでそれらをエスケープする。たとえば、
my_own%dbという名前のデータベースのすべてのテーブルを複製するが、my1ownAABCdbデータベースからはテーブルを複製しないという場合、‘_’ と ‘%’ の文字を をエスケープする。例示すると、--replicate-wild-do-table=my\_own\%dbになる。 コマンド ラインでオプションを使用している場合に、コマンドのインタープリターによっては、ダブル バックスラッシュまたはオプション値を指定する必要がある可能性がある。たとえば、bash シェルの場合、--replicate-wild-do-table=my\\_own\\%dbと入力する。--replicate-wild-ignore-table=db_name.tbl_nameスレーブ スレッドにステートメントを複製しないように指示する。このステートメントは、任意のワイルドカード パターンと一致するテーブルもの。無視するテーブルを一つ以上指定するには、このオプションをそれぞれのテーブル毎に使用する。じれはクロス データベース アップデートでも利用できる。詳細は 項5.5.6. 「サーバのレプリケーション ルール評価」 を参照。
例:
--replicate-wild-ignore-table=foo%.bar%はデータベース名がfooで、テーブル名がbarで、それぞれ始まるテーブルを使用しているアップデートを複製しない。このマッチング (一致) がどのように行われるかは、
--replicate-wild-do-tableの詳細を参照のこと。オプション値にリテラルのワイルドカード文字を含むルールはに関しては、--replicate-wild-ignore-tableと同様である。スレーブ レジストレーションでマスタにレポートするスレーブのホスト名または IP アドレス。この値はマスタ サーバの
SHOW SLAVE HOSTSに出力される。スレーブ自体をマスタとして登録しない場合は、この値をそのままにしておく。スレーブ接続時に、マスタが単にTCP/IP ソケットからスレーブの IP アドレスを読み込む、ということは十分とは言えない。NAT およびルーティングの問題で、この IP はマスタまたは別のホストからスレーブへの接続に対して有効でない可能性がある。スレーブに接続するTCP/IP ポート番号。スレーブ登録でマスタにレポートする。スレーブが非デフォルトのポートでリスニングしている場合、または、マスタもしくは別のクライアントからスレーブへ特別のトンネルがある場合のみに設定する。これについて定かでない場合は、このオプションは使用しない。
スレーブ サーバにサーバ起動時にスレーブ スレッドを開始しないように指示。このスレッドを後で開始するには、
START SLAVEステートメントを使用する。--slave_compressed_protocol={0|1}このオプションが 1 で設定する場合に、スレーブとマスタの両方がこれをサポートするときには、スレーブ/マスタ間に圧縮プロトコールを使用する。デフォルトは 0 (非圧縮)。
スレーブが一時ファイルを作成するディレクトリの名前。このオプションは、デフォルトで
tmpdirシステム変数の値と同等である。スレーブ SQL スレッドはLOAD DATA INFILEステートメントを複製するとき、リレー ログから一時ファイルにロードするファイルを抽出し、それをテーブルにロードする。マスタへのロード ファイルが大きい場合は、スレーブの一時ファイルも大きくなる。そのため、スレーブに一時ファイルを余裕があるファイルシステム内のディレクトリに置くよう指示することを検討するとよい。その場合、リレー ログもまた大きくなるため、そのファイルシステムのリレー ログを置くために--relay-logオプションを使用することを検討する。このオプションで指定するディレクトリはディスク ベースのファイルシステムを使用する。メモリ ベースのファイルシステムは不可。
LOAD DATA INFILEでの複製に使用する一時ファイルは、マシンの再起動に耐える必要があるためである。このディレクトリはまた、システム スタートアップのプロセスでオペレーティング システムによってクリアされたものとは別のものである必要がある。スレーブが読み取りを中止する前に、マスタからのデータを待つ秒数。スレーブが接続切断と判断して再接続を試行するときのもの。最初の接続試行はタイムアウト直後に行われる。再試行のインターバルは、
--master-connect-retryオプションでコントロールできる。再接続の試行回数は--master-retry-countオプションで設定する。デフォルトでは、3600 秒 (1時間)。--slave-skip-errors=[err_code1,err_code2,...|all]通常、スレーブでエラーが起こるとレプリケーションは停止する。これは、データの不一致を手動で解決する機会でもある。このオプションはスレーブ SQL スレッドにオプション値にリスト化したエラーをステートメントが返す場合でも、レプリケーションを続けるよう指示する。
エラーの原因が明確ではない場合は、このオプションを使用しない。レプリケーション セットアップやクライアント プログラムにバグがなく、MySQL自体にもバグがない場合は、レプリケーションを抑制するエラーは起こり得ない。このオプションの無差別的な使用は、スレーブがマスタとの同期化を妨げることに繋がる。そのため、十分な理解が必要である。
エラー コードに関しては、スレーブのエラー ログおよび
SHOW SLAVE STATUS出力のエラー メッセージによって提供される数字を使用する。サーバ エラー コードに関しては Error Codes and Messages を参照のこと。allを使用してスレーブにすべてのエラー メッセージを無視し、何が起きようとも複製を続けるよう指示ことも可能ではあるが、できるだけ、この値の使用は避ける。allを使用するということは、データの整合性を確証できない。これを行ったがために、スレーブとマスタのデータに相違が発生した場合に、バグ報告などでクレームしてはいけない。そのため、十分な注意が必要である。例:
--slave-skip-errors=1062,1053 --slave-skip-errors=all
レプリケーション開始後は、管理者側のタスクをあまり必要としない実行になります。レプリケーション環境にもよりますが、定期的、日常的、またはできる限り、それぞれのスレーブのレプリケーション ステータスをチェックすることをお勧めします。
レプリケーション プロセスを管理するときの一般的なタスクとして、レプリケーションが正確に行われ、スレーブとマスタの間でエラーが発生していないかどうかを確認することがあります。
これに対するプライマリのコマンドは、SHOW
SLAVE STATUS
であり、それぞれのスレーブで実行します。
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: master1
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 931
Relay_Log_File: slave1-relay-bin.000056
Relay_Log_Pos: 950
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 931
Relay_Log_Space: 1365
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
1 row in set (0.01 sec)検査するステータス レポートからのキー フィールド
Slave_IO_State? スレーブのカレント ステータスを示す。 項5.5.3. 「スレーブ レプリケーションの I/O スレッド状態」 および 項5.5.4. 「スレーブ レプリケーションの SQL スレッド状態」 を参照。Slave_IO_Running? マスタのバイナリ ログを読む IO スレッドが実行されているかどうかを示す。Slave_SQL_Running? バイナリ ログのイベントを実行する SQL スレッドが作動しているかどうかを示す。Last_Error? リレー ログを処理したときに最後に登録されたエラーを示す。これがブランクの場合は、エラーがないことを示す。Seconds_Behind_Master? スレーブ SQL スレッドがマスタのバイナリ ログに遅れた時間を示す。この数字が大きい、または上昇している場合は、スレーブがマスタからの大量クエリに対応できないことを示す。
マスタでは、実行プロセスのリストをチェックしてスレーブのステータスを調べることができます。スレーブは
Binlog Dump コマンドを実行します。
mysql> SHOW PROCESSLIST \G;
*************************** 4. row ***************************
Id: 10
User: root
Host: slave1:58371
db: NULL
Command: Binlog Dump
Time: 777
State: Has sent all binlog to slave; waiting for binlog to be updated
Info: NULLスレーブがレプリケーション プロセスの主体として働くため、このレポートの情報には限りがあります。
--report-host
オプションを使用している場合は、SHOW
SLAVE HOSTS
ステートメントが接続しているスレーブに関する基本的な情報を示します。
mysql> SHOW SLAVE HOSTS; +-----------+--------+------+-------------------+-----------+ | Server_id | Host | Port | Rpl_recovery_rank | Master_id | +-----------+--------+------+-------------------+-----------+ | 10 | slave1 | 3306 | 0 | 1 | +-----------+--------+------+-------------------+-----------+ 1 row in set (0.00 sec)
この出力は、スレーブ サーバの ID、
--report-host
オプションの値、接続レポート、マスタ
ID、バイナリ ログ
アップデート受信に関するスレーブの優先順位などを含みます。
STOP SLAVE や START SLAVE
などのコマンドを使用してスレーブにステートメントのレプリケーションの開始、停止を促すことができます。
マスタからのバイナリ
ログの実行を停止するには、STOP
SLAVE を使用します。
mysql> STOP SLAVE;
実行を停止すると、スレーブはマスタからのバイナリ
ログの読み込みを止め
(IO_THREAD)、未処理のリレー
ログのイベント処理を停止します
(SQL_THREAD)。 スレッド
タイプを指定して、IO スレッド、または SQL
スレッドのどちらかを別々に一時停止できます。次はその例です。
mysql> STOP SLAVE IO_THREAD;
SQL スレッドを停止することは、マスタからのイベントのみを処理するスレーブでバックアップなどのタスクを実行するときに便利です。IO スレッドはマスタからの読み込みを続けますが、実行はしません。このため、スレーブのオペレーションを再開するときにスレーブが簡単にキャッチアップできます。
IO スレッドを停止すると、リレー ログが新たなイベントの受信を停止した時点までのリレー ログのステートメントを実行します。このオプションの使用は、実行を一時停止し、スレーブがマスタからのイベントにキャッチアップさせるとき、そして、スレーブでのアドミニストレーション タスクを行うとき、あるいは、特定ポイントまでの最新アップデートを確かめることなどに役立ちます。この方法は、マスタでのアドミニストレーション タスクを行うためにスレーブでの実行を停止するとき、レプリケーションを再開するときに大量にバックログのイベントがあるかどうかを調べるときになどに活用できます。
再開するには、START SLAVE
ステートメントを使用します。
mysql> START SLAVE;
必要に応じて、IO_THREAD または
SQL_THREAD
のどちらかのスレッドを別々に開始できます。
MySQL supports many different topologies for replication. Which topology you use will depend on your requirements and what you want to use replication to achieve.
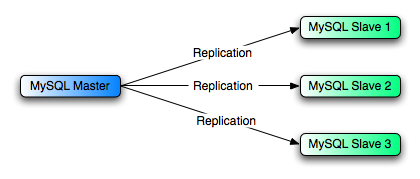
Single slave
Replication with a single slave

Replication with multiple slaves
Replication with multiple masters
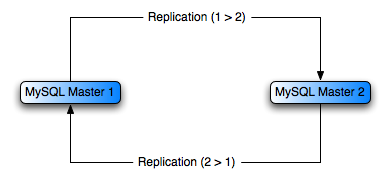
When multiple servers are configured as replication masters,
special steps must be taken to prevent key collisions when using
AUTO_INCREMENT columns, otherwise multiple
masters may attempt to use the same
AUTO_INCREMENT value when inserting rows.
The auto_increment_increment and
auto_increment_offset system variables help
to accommodate multiple-master replication with
AUTO_INCREMENT columns. Each of these
variables has a default and minimum value of 1, and a maximum
value of 65,535.
These two variables affect AUTO_INCREMENT
column behavior as follows:
auto_increment_incrementcontrols the increment between successiveAUTO_INCREMENTvalues.auto_increment_offsetdetermines the starting point forAUTO_INCREMENTcolumn values.
By choosing non-conflicting values for these variables on
different masters, servers in a multiple-master configuration
will not use conflicting AUTO_INCREMENT
values when inserting new rows into the same table. To set up
N master servers, set the variables
like this:
Set
auto_increment_incrementtoNon each master.Set each of the
Nmasters to have a differentauto_increment_offset, using the values 1, 2, …,N.
For additional information about
auto_increment_increment and
auto_increment_offset, see
項4.2.3. 「システム変数」.
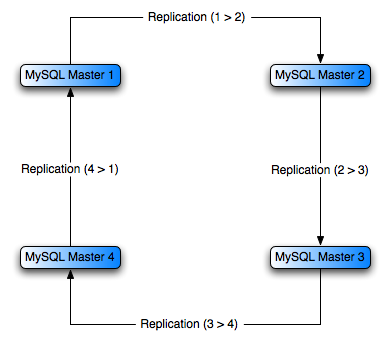
Multiple masters
It is safe to connect servers in a circular master/slave
relationship if you use the --log-slave-updates
option. That means that you can create a setup as shown in
図?5.5. 「Replication with multiple masters in a chain topology」.
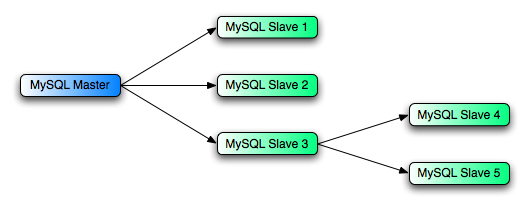
However, many statements do not work correctly in this kind of setup unless your client code is written to take care of the potential problems that can occur from updates that occur in different sequence on different servers.
Server IDs are encoded in binary log events, so server A knows
when an event that it reads was originally created by itself and
does not execute the event (unless server A was started with the
--replicate-same-server-id option, which is
meaningful only in rare cases). Thus, there are no infinite loops.
This type of circular setup works only if you perform no
conflicting updates between the tables. In other words, if you
insert data in both A and C, you should never insert a row in A
that may have a key that conflicts with a row inserted in C. You
should also not update the same rows on two servers if the order
in which the updates are applied is significant.
レプリケーションは広範囲かつ異なる環境で使用できます。この章では、固有のソリューション タイプに対応したレプリケーションの手順に関して、一般的なメモとアドバイスを提供します。
バックアップ環境でのレプリケーションに関する詳細、セットアップ、バックアップ手順、バックアップするファイルに関するノートに関しては、項5.3.1. 「バックアップのレプリケーション」 を参照してください。
マスタとスレーブで異なるストレージ エンジンを使用している場合のアドバイスやヒントは、項5.3.2. 「ストレージ エンジンが異なるマスタとスレーブのレプリケーション」 を参照してください。
スケール アウト ソリューションとしてレプリケーションを使用するには、対象アプリケーションのロジックとオペレーションでの若干の変更が必要になります。詳細は 項5.3.3. 「スケールアウトのレプリケーション」 を参照してください。
パフォーマンスまたはデータ分散などでは、異なるデータベースを異なるレプリケーション スレーブに複製することをお勧めします。詳細は 項5.3.4. 「異なるデータベースから異なるスレーブへのレプリケーション」 を参照してください。
レプリケーション スレーブの数が増えると、それぞれのスレーブにバイナリ ログを複製する必要があるため、マスタでの負荷が増加し、マスタのパフォーマンスが低下することに繋がります。レプリケーション パフォーマンスを改善するヒント、単一のセカンダリ サーバをレプリケーション マスタとして使用する方法に関しては、項5.3.5. 「レプリケーション パフォーマンスの改善」 を参照してください。
非常時のフェイルオーバ ソリューションとして、マスタへの切り替えやスレーブをマスタにするためのガイドは、項5.3.6. 「フェイルオーバでのマスタ切り替え」 を参照してください。
レプリケーションのコミュニケーションを安全に行うには、SSL をデータ交換に使用して通信チャネルを暗号化します。段階的な指示説明は、項5.3.7. 「SSLを使用するレプリケーションの設定」 を参照してください。
レプリケーションは、バックアップ ソリューションとして、マスタからスレーブへデータを複製してデータ スレーブをバックアップできます。スレーブはマスタで稼動しているオペレーションに影響を与えることなく、一時停止やシステム終了ができるため、通常はマスタ データベースのシャツとダウンしなければならない、ライブデータのスナップショットを効率的に生成できます。
データベースをどのようにバックアップするかは、データベースのサイズに依存します。また、データだけをバックアップするのか、予期していないイベントが発生したときにスレーブを立て直すためにデータとレプリケーション スレーブの状態をバックアップするのかなどによって異なります。これには、2 つの選択肢があります。
マスタのデータをバックアップするようにするソリューションとしてレプリケーションを利用する場合には、データベースのサイズが超過している場合は、mysqldump
ツールを使うことをお勧めします。詳細は
項5.3.1.1. 「mysqldump を使用したバックアップ」
を参照してください。
mysqldump
が実用的ではない大型のデータベースには、生データのファイルをバックアップできます。生データ
ファイルのオプションを使用するということは、スレーブ障害のイベントでスレーブを再生できるバイナリ
ログとリレー
ログをバックアップするということです。詳細は
項5.3.1.2. 「生データのバックアップ」
を参照してください。
データベース コピーの作成に mysqldump を使用すると、MySQL の別インスタンスに情報をインポートできる形式に、データベースのデータすべてを取り込むことができます。情報の形式は、SQL ステートメントであるため、緊急にデータへアクセスを必要とするイベントなどで、ファイルを簡単に分散でき、稼動しているサーバで利用できます。しかし、データ サイズが大きい場合は、mysqldump は実用的ではないことがあります。
mysqldump を使用するときには、ダンプ処理を開始する前にスレーブを停止して、ダンプ (出力) に整合データ セットが含まれていることを確認してください。
マスタの処理要求を停止する。または mysqladmin を使用して完全にスレーブを停止する。
shell> mysqladmin stop-slave
別の方法としては、レプリケーション SQL スレッドを停止してリレー ログ ファイルの処理を停止します。この方法は、バイナリ ログのデータの転送を許可します。この方法を活発なレプリケーション環境で使用すると、スレーブ処理を再開をしたときにキャッチ アップ プロセスをスピードアップする可能性があります。
shell> mysql -e 'STOP SLAVE SQL_THREAD;'
データベースをダンプするために、mysqldump を実行する。ダンプするデータベース選択するか、データベースすべてをダンプするかを決める。詳細は 項7.12. 「mysqldump ? データベースバックアッププログラム」 を参照してください。データベースすべてをダンプするには、
shell> mysqldump --all-databases >fulldb.dump
ダンプが完了したら、スレーブのオペレーションを再開する。
shell> mysqladmin start-slave
上記の例示では、ログイン資格情報 (ユーザ名、パスワード) をコマンドに加え、日常、自動的に実行するスクリプトにこのプロセスをバンドルすることができます。
この方法でアプローチするときには、このバックアップの所要時間が、マスタからのイベントに対応しているスレーブの能力への影響を避けるために、スレーブのレプリケーション プロセスを監視してください。詳細は 項5.1.4.1. 「レプリケーション ステータスのチェック」を参照してください。スレーブが遅れる場合には、別のサーバを追加して、バックアップ プロセスを分散することをお勧めします。このシナリオの構成例は、項5.3.4. 「異なるデータベースから異なるスレーブへのレプリケーション」 を参照してください。
MySQL に生データ ファイルをバックアップするときは、コピー ファイルの整合性を確証するために、スレーブ サーバがシステム終了した状態で、レプリケーション スレーブを行います。 MySQL サーバが稼動している場合は、バックグラウンド タスクに、特に InnoDB などのバッグラウンド プロセスを伴うトレージ エンジンなどのときには、データベース ファイルを依然として更新している可能性があります。InnoDB に関しては、これらの問題はクラッシュ リカバリ中に解決するものですが、マスタ側での実行に影響を与えないこと、およびバックアップ プロセス中にスレーブ サーバのシステム終了が可能であることを基に、この利点を生かすことをお勧めします。
サーバのシステム終了とファイルのバックアップ方法
MySQL サーバをシャットダウンする。
shell> mysqladmin shutdown
データ ファイルをコピーする。cp、tar、WinZip などのユーティリティを使用してアーカイブする。
tar cf /tmp/dbbackup.tar ./data
mysqld プロセスを再度立ち上げる。
shell> mysqld_safe &
Windows の場合
C:\> "C:\Program Files\MySQL\MySQL Server 5.1\bin\mysqld"
通常はデータ フォルダ全体をスレーブ MySQL
サーバにバックアップします。スレーブ障害のイベントで、データをリストアしてスレーブとして使うには、スレーブのデータをバックアップするときに、master.info
および relay.info のサーバ
ステータス ファイルをリレー ログ
ファイルとともにバックアップします。これらのファイルは、スレーブのデータをリストアした後、レプリケーションをレジューム
(再開) するときに必要になります。
リレー ログは紛失したが
relay-log.info
ファイルはまだ健在であるという場合には、そのファイルで、マスタのバイナリ
ログでSQL
スレッドがどれくらい実行されたかを調べます。そして、スレーブに起点からのバイナリ
ログを再度読み込むよう指示するために、MASTER_LOG_FILE
および MASTER_LOG_POS オプションと
CHANGE MASTER TO
を使用します。この方法はバイナリ
ログがまだマスタ
サーバに存在している場合だけ有効です。
スレーブが LOAD DATA INFILE
ステートメントの複製に関連している場合は、スレーブが使用しているディレクトリの
SQL_LOAD-*
ファイルもバックアップしてください。そのファイルは、中断した
LOAD DATA INFILE
オペレーションのレプリケーションをレジュームするときに、スレーブが必要とします。ディレクトリの保存場所は、--slave-load-tmpdir
オプションで指定します。指定できない場合は、ディレクトリの保存場所は
tmpdir システム変数の値です。
レプリケーション プロセスは、マスタのソース
テーブルとマスタの複製テーブルが異なるエンジンを使用しているかどうかを重視しません。実際には、システム変数
storage_engine と
table_type は複製されません。
このレプリケーション
プロセスでの優位性を異なるエンジン
タイプでのレプリケーション
シナリオに役立てることができます。たとえば、スケール
アウトのシナリオ
(項5.3.3. 「スケールアウトのレプリケーション」 参照)
では、通常、トランザクション機能をマスタの
InnoDB
テーブルに使いますが、データがリード
オンリーということから、トランザクション
サポートを必要としないスレーブの
MyISAM を使用できます。データ
ロギングの環境でレプリケーションの場合には、スレーブの
Archive ストレージ
エンジンを使うことも可能です。
イニシャル レプリケーション プロセスをどのように設定するかによって、マスタとスレーブでエンジンが異なる場合の設定は異なります。
マスタのデータベース スナップショットを作成する場合は、
mysqldumpを使用して、ダンプ テキストを操作し、それぞれのテーブルで使用しているエンジン タイプを変更します。mysqldumpの別の利点としては、スレーブで使いたくないエンジン タイプを無効にすることができ、これは、スレーブでデータを起こす前にダンプします。 たとえば、InnoDBエンジンを無効にするには、--skip-innodbオプションをスレーブに追加します。 特定のエンジンがない場合、MySQLでは通常、MyISAMなどのデフォルトのエンジン タイプを使います。この方法でそのほかのエンジンを無効にする場合には、そのエンジンをサポートする特別のバイナリをスレーブを使うように構成してください。生データ ファイルをスレーブ集団で使用している場合は、イニシャルのテーブル型を変更することはできません。 その場合は、スレーブが稼動してから、テーブル型の変更に
ALTER TABLEを使います。マスタにテーブルがない時点でのマスタ・スレーブ レプリケーション設定には、新たなテーブルを作成するときのエンジン タイプの指定を避けてください。
レプリケーション ソリューションをすでに実行している場合に既存のテーブルを別のエンジン タイプに変更するには、次のステップに従います。
レプリケーション アップデートの実行からスレーブを停止する。
mysql> STOP SLAVE;
これにより、中断することなく、エンジン タイプの変更が可能になります。
エンジン タイプを変更するテーブルのそれぞれで、
ALTER TABLE ... Engine='を実行する。enginetype'スレーブのレプリケーションを再開する。
mysql> START SLAVE;
storage_engine と
table_type
変数は複製されませんが、エンジンの仕様を含む
CREATE TABLE および ALTER
TABLE
ステートメントはスレーブに正確に複製されます。CSV
テーブルがある場合には次を実行します。
mysql> ALTER TABLE csvtable Engine='MyISAM';
例示のステートメントはスレーブに複製され、そのスレーブのエンジン
タイプは MyISAM になります。CSV
のほかに、スレーブのテーブル型をエンジンにすでに変更していた場合も同様です。
マスタとスレーブでエンジンに違いを付ける場合に、新たなテーブルを作成するときは、マスタの
storage_engine
変数を扱うときには十分に注意してください。
mysql> CREATE TABLE tablea (columna int) Engine=MyISAM;
次のフォーマットを使用します。
mysql> SET storage_engine=MyISAM; mysql> CREATE TABLE tablea (columna int);
複製後、storage_engine
変数は無視され、CREATE TABLE
ステートメントはスレーブのデフォルト
エンジン タイプで実行になります。
スケールアウト ソリューションとしてレプリケーションを使用できるため、データベース クエリ負荷を複数のデータベース サーバに分けることができす。ただし、これには一定の制約があります。
レプリケーションは、ひとつのマスタから複数のスレーブに分散できるため、読み込み頻度が高く、書き込みと更新の頻度が低い場合でのスケールアウトに最適です。ウェブサイトなどはこのカテゴリに該当し、ユーザによるウェブサイトの閲覧、情報取得または入力、製品の検索などに対応します。
書き込みが必要な場合に、ウェブ サーバがレプリケーション マスタと通信する一方で、レプリケーション スレーブが読み込み分を担当します。 このシナリオでのレプリケーション レイアウトのサンプルは 図?5.6. 「スケールアウト レプリケーションのパフォーマンス向上の概略図」 を参照してください。
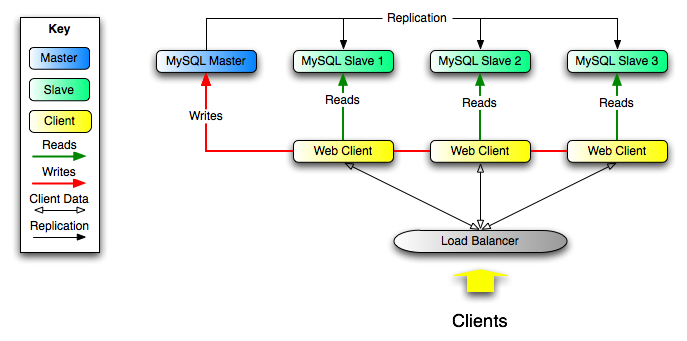
データベース アクセスを担うコードの一部を適当にモジュール化するときは、それを複製したセットアップで実行するよう変換すると、スムーズかつ簡単です。マスタにすべての書き込み分を、そしてマスタまたはスレーブに読み込み分を送るには、データベース アクセスの実装を変更します。 コードでこのレベルの抽出を確保できない場合は、クリーン アップなどのモチベーション向上にもなるので、複製システムをセットアップすることをお勧めします。 次の関数を実装してラッパー ライブラリまたはモジュールを作成することから始めます。
safe_writer_connect()safe_reader_connect()safe_reader_statement()safe_writer_statement()
関数名safe_ の safe_
は、関数がすべてのエラー条件を処理することを意味します。
ここでは、読み取りのための接続、書き込みのための接続、読み取り実行、書き込み実行で統合インタフェースを持つことが重要です。
次に、ラッパー ライブラリを使用するようにクライアントコードを変換します。このプロセスは困難ですが、長期的に見ると有意義です。 ここで説明したアプローチを使用するアプリケーションはすべて、マスタ・スレーブ構成の利点を活用できます。 このコードは保守が非常に簡単で、トラブルシューティング オプションの追加にも手間がかかりません。 つまり、1 つか 2 つの関数を修正するだけで、各クエリに所要時間をログしたり、どのクエリがエラーの原因になったかを特定できます。
コード作成の経験が豊かであれば、MySQL の標準ディストリビューションに含まれている replace ユーティリティを使用して変換タスクを自動化することも可能です。または独自の変換スクリプトを作成することもできますが、その際にはプログラミング コードが一貫して認識できるスタイルが理想的です。そうでない場合は、書き換えることをお勧めしますが、少なくとも 一貫したスタイルに整えてください。
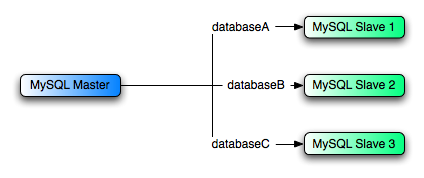
単一のマスタで異なるデータベースを異なるスレーブに複製する場合には、たとえば、異なる販売データを別の部署へ配布すときにはデータ分析の負荷を低減することになります。このレイアウトは 図?5.7. 「別々の DB を複数のホストに複製するレプリケーション概略図」 を参照してください。
マスタとスレーブを普通に構成し、セパーレションを行い、replicate-wild-do-table
コンフィギュレーションをそれぞれのスレーブに使用して、それぞれのスレーブが処理するバイナリ
ログ ステートメントを制限します。
たとえば、図?5.7. 「別々の DB
を複数のホストに複製するレプリケーション概略図」
で示すようにセぱレーションをサポートするには、START
SLAVEを使用して複製を可能にする前に、次のようにそれぞれのスレーブを構成します。
MySQL Slave 1 には、次のコンフィギュレーション オプションが必要。
replicate-wild-do-table=sales.% replicate-wild-do-table=finance.%
MySQL Slave 2 には、次のコンフィギュレーション オプションが必要。
replicate-wild-do-table=support.%
MySQL Slave 3 には、次のコンフィギュレーション オプションが必要。
replicate-wild-do-table=service.%
レプリケーションを開始する前にスレーブ’と同期しなければならないデータがある場合は、いくつかのオプションがあります。
それぞれのスレーブとすべてのデータを同期化し、不要なデータベースまたはテーブル、あるいはその両方を削除する。
それぞれのデータベース用に別々のダンプ ファイルを作成するために、
mysqldumpを使用し、それぞれのスレーブに適切なダンプ ファイルをロードする。生データ ファイル ダンプを使用し、それぞれのスレーブで必要とする指定ファイルとデータベースを入れる。これは、
innodb_file_per_tableオプションを使用すると、InnoDB でも機能します。
このコンフィギュレーションのスレーブは、マスタからのバイナリ ログ全体へ転送しますが、構成したデータベースとテーブルに適用する範囲のバイナリ ログのイベントだけを実行します。
マスタに接続したスレーブの数が増えると、若干の負荷も同様に増え、それぞれのスレーブがマスタへのクライアント コネクションを使い切ります。さらに、それぞれのスレーブはマスタのバイナリ ログの完全なコピーを受け取る必要があるめ、マスタのネットワーク負荷も同様に増え、ボトルネックを生成しシステム全体の性能が低下します。
スケール アウト ソリューションなどで、マスタに接続しているスレーブの数が多いときは、それに対応してマスタでの処理量は膨大になるため、レプリケーション プロセスのパフォーマンスを改善することをお勧めします。
レプリケーション プロセスのパフォーマンスを改善する方法の一つには、よりディープなレプリケーション ストラクチャを構築することがあります。これは、マスタが一つのスレーブにだけ複製を行い、ほかのスレーブは個別のレプリケーション要求に対応するプライマリ スレーブに接続するという方法です。このストラクチャのサンプルは 図?5.8. 「追加のレプリケーション ホストでパフォーマンス改善」 を参照してください。
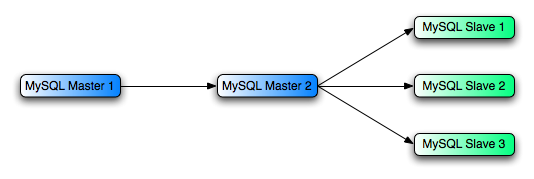
これを実現するには、MySQL インスタンスを次のように設定します。
Master 1 はプライマリ マスタで、このデータベースにすべての変更とアップデートが書き込まれます。バイナリ ロギングはこのマシンで実行可能にします。
Master 2 は Master 1 へのスレーブです。Master 1 はレプリケーション ストラクチャにおいて、レプリケーションの機能性をスレーブの残留分に提供します。ここで Master 2 は Master 1 に唯一接続しているマシンです。Master 2 はバイナリ ロギングが可能な状態です。
--log-slave-updatesオプション で Master 1 からの複製指示が Master 2 のバイナリ ログに書き込まれ、これにより、両者が正当なスレーブに複製するようになります。Slave 1、Slave 2、Slave 3 は Master 2 のスレーブとして稼動し、Master 2 からの情報を複製しますが、実際には Master 1 でログしたデータです。
このソリューションは、プライマリ マスタのクライアント負荷だけでなくネットワーク インターフェイス負荷を減らすことができ、プライマリ マスタのパフォーマンス全体を改善するダイレクト データベース ソリューションとして活用できます。
マスタのレプリケーション プロセスに追いつくことに支障をきたしているスレーブがある場合には、次のオプションで対応します。
リレー ログとデータ ファイルをできるだけ物理的に独立したドライブに割り振ります。そのためには、
--relay-logオプションを使用して、リレー ログの保管場所を指定します。スレーブがマスタよりも特段に遅い場合は、データベースの種類にあわせて複製の役割を別のスレーブに分けることをお勧めします。詳細は 項5.3.4. 「異なるデータベースから異なるスレーブへのレプリケーション」 を参照してください。
マスタのトランザクションを活用し、スレーブがそのトランザクション サポートをしているかどうかを確かめるには、
MyISAMまたはその他の非トランザクション エンジンを使用します。詳細は 項5.3.2. 「ストレージ エンジンが異なるマスタとスレーブのレプリケーション」 を参照してください。スレーブがマスタとして稼動していない状況で、なにかしら対処できる方法があり、障害イベント中のマスタを持ち込むことができる場合には、
--log-slave-updatesオプションをオフにします。これは、“処理能力のない”スレーブがまた、それぞれのバイナリのログに実行したイベントを記録することを防ぎます。
障害が発生した場合にマスタとスレーブ間でのフェイルオーバに対応する正式なソリューションは現在の段階ではありません。現在利用可能な機能内では、マスタとスレーブ (または複数のスレーブ) をセットアップし、状況を把握するためにマスタを監視するスクリプトを作成することが挙げられます。そのときには、アプリケーションとスレーブに障害を認識した場合にマスタを変更するよう指示します。
CHANGE MASTER TO
ステートメントを使用して、いつでもスレーブにマスタを変えるように指示することが重要です。スレーブはマスタのデータベースがスレーブとの互換性を保持しているかどうかを確認することができないため、新しいマスタが指定するログと場所からイベントを実行し始めます。フェイルオーバの状況で、グループ内すべてのサーバが同一のバイナリ
ログからの同一のイベントを実行しています。そのため、イベント元の変更がデータベース
ストラクチャまたは整合性に影響することのないように慎重に扱う必要があります。
スレーブを --log-bin はあるけれども
--log-slave-updates
はないという組み合わせで実行します。この方法では、スレーブで
RESET MASTER と CHANGE MASTER
TO を実行し、別のスレーブで STOP
SLAVE
を実行すると同時に、スレーブがマスタになる準備ができます。図?5.9. 「レプリケーションを活用した冗長性、初期ストラクチャ」
のストラクチャで例示を参照してください。
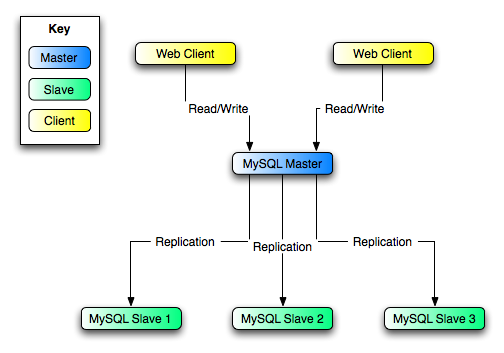
この図では、MySQL Master にはマスタ
データベースがあり、MySQL Slave
のコンピュータはレプリケーション
スレーブ、そして Web Client
マシンは読み書き込みをするデータベースという関係になります。通常スレーブに接続していて読み込みだけを行うウェブ
クライアントは、障害イベントで新しいサーバへは切り替わらないため、図には含まれていません。読み書き込みのスケールアウト
ソリューション
ストラクチャに関しては、項5.3.3. 「スケールアウトのレプリケーション」
を参照してください。
MySQL Slave のそれぞれ (Slave
1、Slave 2、Slave
3) は、 --log-slave-updates
を伴わずに、--log-bin
だけで実行しているスレーブです。--log-slave-updates
の指定がなければマスタからスレーブが受信したアップデートがバイナリ
ログに記録されないため、それぞれのスレーブのバイナリ
ログは最初から空です。 何らかの原因により
MySQL Master
が利用不可になる場合、複数あるスレーブの中から新しいマスタを選ぶことができます。たとえば、Slave
1 を選択する場合、すべての Web
Clients を Slave 1
にリダイレクトして、そこのバイナリ ログ
にアップデートを記録します。つまり、Slave
2 と Slave 3 は Slave
1 から複製することになります。
--log-slave-updates
なしで実行するという理由には、複数のスレーブの中から一つが新たなマスタに切り替わるときに、アップデートを
2
度受信しないようにするためです。たとえば、Slave
1 は --log-slave-updates
するようになると、Master
から受信するアップデートを自分のバイナリ
ログに書き込みます。Slave 2 が
Master から Slave 1
に切り替わった場合は、Master
からアップデートをすでに受信しているにも関わらず、Slave
1
から再度、アップデートを受信するという結果になります。
すべてのスレーブがリレー
ログ内のクエリを処理したかどうかを確認してください。それぞれのスレーブでは、STOP
SLAVE IO_THREAD を発行して、Has read all
relay log を確認できまるまで、SHOW
PROCESSLIST の出力をチェックします。
すべてのスレーブでこれが確認できたら、これらを新たな設定として構成できます。マスタに昇格した
Slave 1 のスレーブでは、STOP
SLAVE と RESET MASTER
を発行します。
別のスレーブ Slave 2 と Slave
3 では、STOP SLAVE
とCHANGE MASTER TO
MASTER_HOST='Slave1' を使います。
('Slave 1'
が、Slave1
の実際のホスト名を表示する場合).CHANGE
MASTER には、Slave 2 または
Slave 3 から Slave 1
へのどのようにするかに関するすべての情報を付加します。(user、password、port
など) CHANGE MASTER では、Slave
1 のバイナリ
ログ名や読み込み先のバイナリ
ログ位置を指定する必要はありません。CHANGE
MASTER
のデフォルトでは、一番初めのバイナリ
ログ、そして位置は 4
です。そして最後に、Slave 2 と
Slave 3 で START SLAVE
を使用します。
新たなレプリケーションを整えた後に、Web
Client が Slave 1
へクエリを送信するよう指示します。この時点から、Web
Client が Slave 1
へ送信したすべてのアップデート クエリが
Slave 1 のバイナリ
ログに書き込まれ、すでに Master
は機能していないため、Slave 1
へ送信したすべてのアップデート
クエリが含まれることになります。
サーバ ストラクチャの結果は 図?5.10. 「レプリケーションを活用した冗長性、マスタ障害後」 に示す通りです。
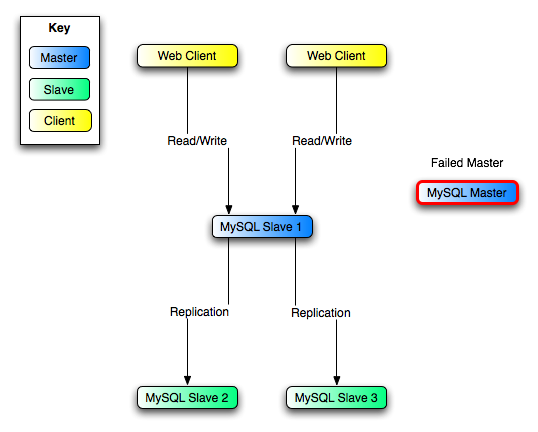
Master
マスタの再稼動するときは、Slave 2
と Slave 3
に発行した通りに、同様の CHANGE
MASTER
を発行してください。これにより、Master
はスレーブの S1
になり、ダウン後に実行された Web
Client の書き込みをすべてピック
アップします。
たとえば、マスタが最もパワフルなマシンであるなど物理的な理由で、Master
をマスタへ戻すには、Slave 1
を利用不可の状態、Master
が新たなマスタになる、というようにそれぞれの立場を逆にしてこの手順を繰り返します。
この手順では、Slave 1、Slave
2 そして Slave 3 を
Master
のスレーブにする前に、Master に
RESET MASTER
を実行することを忘れないでください。これをしないと、Master
が動かなくなる前の古い Web Client
書き込みをピック アップすることになります。
複数スレーブとマスタは同期していません。スレーブのいくつかは他のスレーブよりも前に出ていることがあります。つまり、前述の例で示したコンセプトが機能しない可能性があるということです。しかし、実情では、複数スレーブのリレー ログがマスタからそれほど遅れをとらないので、この方法が適用できるとの考えに基づいています。そのため、この方法が確証できるものではないことに留意してください。
動的な DNS
エントリをマスタに持たせると、マスタの位置に応じてアプリケーションを調節することをお勧めします。bind
で、 DNS を動的に更新するnsupdate
を使います。
クライアントとサーバの SSL と同様に SSL 接続を使用してレプリケーションをセットアップします。マスタに使用する適切なセキュリティ証明書、ならびに同類の証明書を同一の認証機関から、それぞれのサーバ用に取得します。
レプリケーションに必要なバイナリ ログの暗号化トランスファに SSL を使用するには、まず最初に SSL ネットワークをサポートするようにマスタをセットアップします。SSL 用にコンパイルしていない、あるいは構成していないなどの理由で、マスタが SSL 接続をサポートしない場合は、SSL 接続を介してレプリケーションを行うことはできません。
サーバとクライアントの SSL 接続 をセットアップに関する詳細は、項4.8.7.2. 「SSL接続」 を参照してください。
SSL
をマスタで利用可能にするには、適切な証明書を用意して、次に示すコンフィギュレーション
オプションを mysqld
セクション内にあるマスタのコンフィギュレーションに付加します。
ssl-ca=cacert.pemssl-cert=server-cert.pemssl-key=server-key.pem
オプションは次の通りです。
ssl-caが CA 証明書 を認識する。ssl-certがサーバのパブリック キーを認識する。これをクライアントに送信すると、そこにある CA 証明書を認証する。ssl-keyがサーバ プライベート キーを認識する。
スレーブでは、SSL 情報の設定に 2
つのオプションがあります。スレーブの証明書をスレーブのコンフィギュレーション
ファイルの client
セクションに付加するか、もしくは CHANGE
MASTER ステートメント を使って SSL
情報を明確に指定します。
前述のオプションを使用して、次の文字列をスレーブのコンフィギュレーション
ファイルの client
セクションに付加します。
[client] ssl-ca=cacert.pemssl-cert=server-cert.pemssl-key=server-key.pem
スレーブ サーバ
を再稼動し、--skip-slave
をスレーブがマスタへ接続しないようにします。CHANGE
MASTER
を使用して、マスタのコンフィギュレーションを指定し、master_ssl
オプションを使用して、SSL
接続ができるようにします。
mysql> CHANGE MASTER TO \
MASTER_HOST='master_hostname', \
MASTER_USER='replicate', \
MASTER_PASSWORD='password', \
MASTER_SSL=1;
CHANGE MASTER コマンドで、SSL
証明ルールを指定するには、SSL
ルールを付加します。
CHANGE MASTER TO \
MASTER_HOST='master_hostname', \
MASTER_USER='replicate', \
MASTER_PASSWORD='password', \
MASTER_SSL=1, \
MASTER_SSL_CA = 'ca_file_name', \
MASTER_SSL_CAPATH = 'ca_directory_name', \
MASTER_SSL_CERT = 'cert_file_name', \
MASTER_SSL_KEY = 'key_file_name';マスタの情報が更新されたら、スレーブのレプリケーション プロセスを開始します。
mysql> START SLAVE;
SHOW SLAVE STATUS を使用して、SSL
接続が完了したかどうかを確認します。
CHANGE MASTER TO
構文に関する詳細は項12.6.2.1. 「CHANGE MASTER TO 構文」
を参照してください。
レプリケーション中に使用する SSL 接続
を強化する場合は、REPLICATION SLAVE
権限でユーザを作成し、そのユーザ に
REQUIRE_SSL ルールを使用します。
mysql> GRANT REPLICATION SLAVE ON *.*
-> TO 'repl'@'%.mydomain.com' IDENTIFIED BY 'slavepass' REQUIRE SSL;- 5.4.1.1. レプリケーションと
AUTO_INCREMENT - 5.4.1.2. レプリケーションとキャラクタ セット
- 5.4.1.3. レプリケーションと
DIRECTORY構文 - 5.4.1.4. 浮動小数点でのレプリケーション
- 5.4.1.5. レプリケーションと
FLUSH - 5.4.1.6. レプリケーションとシステム機能
- 5.4.1.7. マスタがクラッシュ中のレプリケーション
- 5.4.1.8. マスタのシャットダウン中のレプリケーション
- 5.4.1.9.
MEMORYテーブル型でレプリケーション - 5.4.1.10. システム
mysqlデータベース レプリケーション - 5.4.1.11. レプリケーション中のスレーブ エラー
- 5.4.1.12. スレーブのシャットダウン中のレプリケーション
- 5.4.1.13. レプリケーションとテンポラリ テーブル
- 5.4.1.14. レプリケーション リトライとタイムアウト
- 5.4.1.15. レプリケーションとタイム ゾーン
- 5.4.1.16. レプリケーションとトランザクション
- 5.4.1.17. スレーブの複数カラムでレプリケーション
- 5.4.1.18. レプリケーションと変数
- 5.4.1.19. レプリケーションとビュー
SQL
レベルでのレプリケーション互換性では通常、マスタおよびスレーブの両方のサーバでサポートする機能を必要とします。マスタ
サーバの機能がMySQLのバージョン内で使用可能である場合は、古いバージョンのスレーブに複製することはできません。このような非互換はシリーズ間で起こる可能性が高いため、MySQL
5.1 から 5.0
への複製はできません。しかし、非互換はシリーズ内でのレプリケーションでも発生する可能性があります。例:
SLEEP() 機能は、MySQL 5.0.12
以降のバージョンでのみ使用できます。そのため、マスタ
サーバでこの機能を使用する場合に、サーバが
MySQL 5.0.12
以前のバージョンの場合には複製できません。
5.1 とこれより古いバージョンの MySQL でレプリケーションを行う場合は、その古いバージョンの MySQL レファレンス マニュアルで複製機能に関する情報を確認してから、実行してください。
以下のセクションでは、なにがサポートされているか、そしてなにがサポートされていないかを説明するとともに、複製中に起こる可能性のある問題と状況について説明します。レプリケーションのInnoDBに特化した情報に関しては、項13.5.6.5. 「InnoDB と MySQL 複製」を参照してください。
既存の MySQL でのステートメント ベースの複製に関しては、保存したルーチンとトリガの複製で問題が発生する可能性があります。この問題は、MySQL の行ベースの複製を行うことで回避できます。この問題に関する詳細は、項17.4. 「ストアドルーチンとトリガのバイナリログ」 を参照してください。行ベース レプリケーションに関する詳細は、項5.1.2. 「レプリケーション フォーマット」を参照してください。
レプリケーションは、AUTO_INCREMENT、LAST_INSERT_ID()
そして TIMESTAMP
の値で正しく実行されますが、次のことに留意してください。
LAST_INSERT_ID()
を使用した格納手順は、ステートメント
ベースのバイナリ
ロを使用した場合に正しく複製できません。この制約は、MySQL
5.1.12 で修正の予定です。
AUTO_INCREMENT カラムを ALTER
TABLE
でテーブルに加える場合には、行の順序がスレーブとサーバで同じにならない可能性がある。これは、行の順序が、
テーブルに使う特定の記憶エンジンあるいは行が挿入された順番に依存する場合に発生します。マスタとスレーブで同じ順序に並べる必要がある場合は、AUTO_INCREMENT
番号を割り当てる前に行を整列してください。テーブル
t1に AUTO_INCREMENT
を加えると仮定した場合、t1
と同一の新たなテーブル t2
を、AUTO_INCREMENT
のカラムで、次のステートメントがこれを可能にします。
CREATE TABLE t2 LIKE t1; ALTER TABLE t2 ADD id INT AUTO_INCREMENT PRIMARY KEY; INSERT INTO t2 SELECT * FROM t1 ORDER BY col1, col2;
これは、テーブル t1 にカラム
col1 および col2
があると仮定しています。
重要マスタとスレーブの両方で同一の順番を確保するには、t1
のすべてのカラムが ORDER
BY
節でレファレンスしている必要があります。
ここで示された手順は、CREATE TABLE ...
LIKE 制限を対象としています。DATA
DIRECTORY および INDEX DIRECTORY
テーブル
オプションと同様に、外部キーの定義を無視します。テーブル定義がこれらの特性を含む場合、t1
に使用したものと同一の CREATE
TABLE 構文を使用して t2
を作成しますが、そのときはAUTO_INCREMENT
カラムの追加として行います。
AUTO_INCREMENT
属性をカラムに持つコピーを作成し、投入することに使用した方法に関係なく、このファイナル
ステップは、オリジナルのテーブルをドロップしてから、そのコピーの名前を変更します。
DROP t1; ALTER TABLE t2 RENAME t1;
項B.1.7.1. 「Problems with ALTER TABLE」も参照してください。
以下は、異なるキャラクタ セットを使用している MySQL サーバ間でのレプリケーションに該当します。
マスタで MySQL 4.1 が作動している場合、スレーブで作動している MySQ Lバージョンに関係なく、常に同一のグローバルキャラクタ セットとコレーション (照合順序) をマスタとスレーブに使用します。(これらは、
--character-set-serverおよび--collation-serverオプションがコントロールします。)これ以外の場合は、マスタのキャラクタ セットのユニーク キーが、スレーブのキャラクタ セットではユニークではないと認識する可能性があるため、スレーブで重複キー エラーが発生することがあります。ノート: マスタとスレーブの両方が MySQL 5.0 以降のバージョンである場合は、この心配は不要です。MySQL 4.1.3 より古いバージョンのマスタでは、クライアントのキャラクタ セットのグローバル値が異なると、スレーブではそのキャラクタ セットの変更を認識しません。そのため、
SET NAMESやSET CHARACTER SETなどをクライアントに使用しないでください。マスタとスレーブの両方が 4.1.3 以降である場合、クライアントはキャラクタ セット変数のセッション値を自由に設定できます。これは、これらの設定がバイナリ ログに書き込まれるため、スレーブが認識することに基づきます。つまり、クライアントはSET NAMESあるいはSET CHARACTER SETを使用でき、collation_clientあるいはcollation_serverなどで変数設定ができます。しかし、前述のように、クライアントではこれら変数のグローバル値を変更できないため、マスタとスレーブでは常に同一のグローバル キャラクタ セット値を使用する必要があります。character_set_serverのグローバル値とは異なるキャラクタ セットでマスタのデータベースを使用している場合は、CREATE TABLEコマンドを設計する必要があります。その設計で、データベースのテーブルはデータベースのデフォルトのキャラクタ セットに定義的に依存することがなくなります。推奨の回避方法としては、CREATE TABLE構文でキャラクタ セットとコレーションを定義することをお勧めします。
DATA DIRECTORY または INDEX
DIRECTORY のテーブル オプションをマスタ
サーバの CREATE TABLE
構文で使用している場合、スレーブでもそのテーブル
オプションを使用します。これは、スレーブ
ホストのファイル
システムに対応するディレクトリが存在しない場合、またはディレクトリは存在するがスレーブ
サーバにアクセスできない場合に、問題を引き起こす可能性があります。MySQL
は NO_DIR_IN_CREATE と呼ばれる
sql_mode
オプションをサポートしています。スレーブ
サーバが実行可能な SQL
モードで作動している場合は、CREATE
TABLE ステートメントを複製する際に
DATA DIRECTORY と INDEX
DIRECTORY のテーブル
オプションを無視します。その結果、テーブルのデータベース
ディレクトリには、MyISAM
データとインデックス
ファイルが作成されます。
浮動小数点は近似値であるため、これを利用した比較には誤差が生じます。明示的に浮動小数点を使用する操作、または暗黙的に浮動小数点に変換した値を使用する操作では正当です。コンピュータのアーキテクチャや MySQL のビルドに使用したコンパイラの違いなどにより、浮動小数点での比較はマスタとスレーブで異なる結果を引き起こす可能性があります。項11.1.2. 「式評価でのタイプ変換」 および 項B.1.5.8. 「Problems with Floating-Point Comparisons」 を参照してください。
FLUSH
コマンドのいくつかのフォームは万が一スレーブに複製がされた場合に問題を引き起こす可能性があるため、ログの対象ではありません。(例:
FLUSH LOGS、FLUSH
MASTER、FLUSH SLAVE および
FLUSH TABLES WITH READ
LOCK)構文例は、項12.5.5.2. 「FLUSH 構文」
を参照してください。FLUSH
TABLES、ANALYZE
TABLE、OPTIMIZE TABLE そして
REPAIR TABLE のコマンドはバイナリ
ログに書き込まれ、スレーブに複製します。これらのコマンドはテーブル
データを修正しないため、通常は問題にはなりません。しかし場合によっては、何かしらの問題を伴う可能性があります。mysql
データベースの権限テーブルを複製し、GRANT
を使用しないでテーブルを直接更新する場合は、新たな権限を有効にするために、FLUSH
PRIVILEGES
をスレーブで実行してください。また、MERGE
テーブルにある MyISAM
テーブルの名前を変更する場合に FLUSH
TABLES を使用するときは、FLUSH
TABLES
をスレーブで手動で行います。NO_WRITE_TO_BINLOG
もしくはエイリアスの
LOCALを指定しない場合は、このコマンドはバイナリ
ログに書き込まれます。
一定の条件下では、特定の機能が複製できないことがあります。
USER()、CURRENT_USER()、UUID()そしてLOAD_FILE()関数は、 変更のない複製を行うため、スレーブでは確実には機能しません。列ベースのレプリケーションが使用可能な場合はこの限りではありません。詳細は、項5.1.2. 「レプリケーション フォーマット」 を参照してください。ロギングに関してはコマンド ベースから行ベースに形式移行しないため、混在形式ロギングの初期実行段階の格納関数、トリガそしてこれらを主体とした関数を使用するビューは、混在形式のロギング モードでは確実に複製されません。たとえば、
INSERT INTO t SELECT FROM vのvがUUID()を選択するビューの場合、問題を引き起こす可能性があります。この制約は、MySQL 5.1.12 で修正の予定です。NOW()ではなく、SYSDATE()関数の場合は、バイナリ ログのSET TIMESTAMPコマンドに影響を受けないこと、そしてコマンド ベースのロギングが使用された場合に非決定性であることから、レプリケーション セーフではありません。行ベースのロギングを使用している場合には、この点の心配はありません。もう一つのオプションには、SYSDATE()がNOW()のエイリアスになることをもたらす--sysdate-is-nowオプションでサーバを起動する方法もあります。以下の制約はステートメント ベースのレプリケーションを行うときに該当します。行ベースのレプリケーションには該当しません。
GET_LOCK()、RELEASE_LOCK()、IS_FREE_LOCK()、IS_USED_LOCK()などユーザ レベルでロックを処理する関数の場合には、スレーブはマスタの並列化の前後関係を認識しないまま複製を行います。これにより、スレーブの内容がマスタのものとは異なることになり、これらの関数をマスタのテーブルに挿入するためには使用しないでください。(例:INSERT INTO mytable VALUES(GET_LOCK(...))のようなコマンドは使わない)
ステートメント
ベースのレプリケーションが有効である場合は、前述の制約への代替方法として、ユーザ変数に問題を起こす関数を使い、後続のコマンドなどでユーザ変数を参照する方法があります。以下は、INSERT
一行挿入が UUID()
関数に対して問題があるとした場合の例示です。
INSERT INTO t VALUES(UUID());
この問題を回避するには、次のことを行います。
SET @my_uuid = UUID(); INSERT INTO t VALUES(@my_uuid);
このシーケンスのコマンドは@my_uuid
という値がバイナリ ログに INSERT
コマンドより前のユーザ変数イベントとして格納され、INSERT
で使用可能になるため、複製できます。
この考え方は、複数行の挿入に適用できますが、扱いがより複雑になります。そのため、2行挿入の場合は、次のように行うことができます。
SET @my_uuid1 = UUID(); @my_uuid2 = UUID(); INSERT INTO t VALUES(@my_uuid1),(@my_uuid2);
この方法は行数が大きいまたは未知である場合には実用的ではありません。そのため、それぞれの行に関連するユーザ変数が与えられている場合は、次の例で示すようにコマンドを変更することはできません。
INSERT INTO t2 SELECT UUID(), * FROM t1;
マスタ側でクラッシュした場合は、マスタのバイナリ
ログ
ファイルをフラッシュしていないときには、スレーブで読み込みをした位置より古い位置をマスタのバイナリ
ログに送る原因となります。これは、マスタが戻ってきた場合に、スレーブで複製できなくなる可能性があります。sync_binlog=1
をマスタの my.cnf
ファイルに設定し、マスタがバイナリ
ログを頻繁にフラッシュするように設定すると、この問題は最小化できます。
マスタ
サーバをシャットダウンして、後で起動することは安全です。スレーブ
-
マスタの接続が切断した場合、スレーブは直ちに再接続を試行し、それに失敗すると、定期的に再試行を続けます。デフォルト設定では、60
秒に一度の再試行します。これは、--master-connect-retry
オプションで変更できる可能性があります。スレーブはネットワーク接続の出力停止に対応できる能力があります。しかし、スレーブはネットワーク出力停止から
slave_net_timeout
秒間が経過し、マスタからデータを受信できないことを確認した時点で、ネットワーク出力の停止を認識します。停止時間が短い場合は、slave_net_timeout
を減らすことをお勧めします。詳細は
項4.2.3. 「システム変数」
を参照してください。
サーバがシャットダウンし、再起動するとき、サーバの
MEMORY
テーブルは空になります。このときマスタはこのエフェクトを次のようにして、スレーブに複製します。起動後マスタがそれぞれの
MEMORY を最初に使用する場合、
マスタはイベントをログし、スレーブにテーブルを空にする必要があることを、DELETE
コマンドをバイナリ
ログへのテーブルに書き込むこと通知します。MEMORY
テーブルに関する詳細は、項13.7. 「MEMORY (HEAP)
ストレージエンジン」
を参照してください。
MySQL 5.1.14 以上は、mysql
データベースは複製できません。mysql
データベースはノード固有のデータベースとして扱います。行ベースのレプリケーションはこのテーブルでは使用できません。これに対応する方法として、情報
(GRANT、REVOKE を含む)
を更新するステートメント、トリガ操作、格納ルーチンやプロシージャ、そしてビューは、ステートメント
ベースのレプリケーションを使用して、すべてスレーブに複製する作業を行います。
MySQL 5.1.13 以前では、mysql
データベースが複製された場合に限り、ユーザ権限を複製します。つまり、GRANT、REVOKE、SET
PASSWORD、CREATE
USER、DROP USER
などのコマンドは、mysql
データベースを含んだレプリケーション設定をした場合に限り、スレーブで有効になります。
すべてのデータベースを複製する場合に、ユーザ権限に影響するステートメントを不要とするときは、--replicate-wild-ignore-table=mysql.%
オプションを使用して、スレーブが
mysql
データベースを複製しないように設定します。このスレーブは、権限に関連する
SQL
コマンドを実行することは有効ではない、と認識するため、そのクエリは実行されません。
スレーブのステートメントによりエラーが発生する場合は、スレーブの
SQL
スレッドは処理を終了し、スレーブはそのメッセージをエラーログに書き込みます。その場合は、手動でスレーブ接続を行い、問題の原因を特定します。(そのときには、SHOW
SLAVE STATUS
を使用することをお勧めします。そして、仮想テーブルを作成する必要があるなど、問題に解決策を投じてから、START
SLAVE を実行します。
スレーブはどこでレプリケーションが終了したかを記録しているため、シャットダウンがクリーンに行われた場合は安全です。クリーンではない
(不明確な)
シャットダウン、特に、システム終了前にディスク
キャッシュがフラッシュされていない場合には、問題を引き起こす可能性があります。高性能の無停電電源装置を使用すると、システムのフォールト
トレランス (耐障害性)
は向上します。マスタでの不明確なシステム終了は、マスタ内のテーブル内容とバイナリ
ログ間での不一致を引き起こしますが、これは、InnoDB
テーブルと --innodb-safe-binlog
オプションをマスタで使用することで避けることができます。詳細は
項4.11.4. 「バイナリ ログ」 を参照してください。
この項目は、行ベースのレプリケーションを使用している場合にはテンポラリ テーブルを複製できないため、該当しません。(項5.1.2. 「レプリケーション フォーマット」 を参照してください。)
テンポラリ テーブルの複製は可能ですが、スレーブ スレッドだけでなく、スレーブ サーバをシャットダウンした場合や、テンポラリ テーブルを既に複製していて、そのテーブルを更新などに使用し、それがまだスレーブで実行されていないという場合にはできません。スレーブ サーバをシャットダウンする場合、更新対象のテンポラリ テーブルはスレーブを再起動するときには、すでに利用できない状態になります。この問題を回避するには、テンポラリ テーブルが開いている状態でスレーブをシャットダウンしないよう注意が必要です。代替方法として、次の手順を使用します。
STOP SLAVEステートメントを実行する。SHOW STATUSを使用して、Slave_open_temp_tables変数の値を調べる。値が 0 であれば、 mysqladmin shutdown コマンドを実行して、スレーブを停止する。
値が 0 でなければ、
START SLAVEでスレーブ スレッドを再開する。この手順を繰り返し、
Slave_open_temp_tables変数が 0 になったら、スレーブを停止する。
グローバル システム変数
slave_transaction_retries
はレプリケーションに影響します。InnoDB
デッドロック、InnoDB
innodb_lock_wait_timeoutの値を超過、NDBCluster
TransactionDeadlockDetectionTimeout
もしくは TransactionInactiveTimeout
の値を超過したときなど、 スレーブ SQL
スレッドのレプリケーションでトランザクションに失敗した場合、そのトランザクションは、エラー停止する前に、自動的に
slave_transaction_retries
回の再試行の対象になります。デフォルト値は
10 です。合計再試行の回数は SHOW
STATUS
の出力で確認できます。(項4.2.5. 「ステータス変数」
を参照)
マスタが MySQL 4.1
を使用している場合、マスタとスレーブの両方を同じシステムのタイム
ゾーンで設定する必要があります。両者のタイム
ゾーンが異なる場合、ステートメントの正確な複製はできません。NOW()
または FROM_UNIXTIME()
関数を使用しているステートメントがこれに該当します。mysqld_safe
スクリプトの
--timezone=
オプションを使用するか、 timezone_nameTZ
環境変数を設定すると、作動している MySQL
サーバのタイム
ゾーンで設定できます。マスタとスレーブは同一のデフォルト接続のタイム
ゾーンである必要があり、つまり
--default-time-zone
のパラメータが同一の値である必要があります。これは、マスタが
MySQL 5.0 以降である場合には不要です。
マスタとスレーブの両方が MySQL 5.0.4
以降である場合は、CONVERT_TZ(...,...,@@session.time_zone)
は正確に複製できます。
スレーブの非トランザクションのテーブルを使用して、マスタにトランザクション
テーブルを複製することが可能です。たとえば、InnoDB
マスタ テーブルを MyISAM スレーブ
テーブルとして複製できます。しかし、これを行う場合、スレーブが
BEGIN あるいは COMMIT
セグメントの最中に停止した場合は問題が生じます。これは、スレーブが
BEGIN
セグメントの開始時点で再開することに起因します。
トランザクションと非トランザクションのテーブルへ混在した更新が行われる場合には、バイナリ
ログのクエリ順序が正確になり、必要とされるすべてのクエリがバイナリ
ログに書き込まれます。ROLLBACKの場合でも同様です。しかし、最初のトランザクションが完了する前に
2 番目の接続が非トランザクション
テーブルの更新をすると、ステートメントは順番が乱れた状態での記録になります。これは、最初の接続でのトランザクションの状況に関わらず、2
番目の接続の更新実行と書き込みが同時に発生することに起因します。
MyISAM
テーブルの非トランザクション性により、部分的にテーブルを更新しエラー
コードを返すコマンドを保持することがあります。これは、挿入する複数行にキー制約に違反してる、または長文の更新クエリで数行を更新したあとに落とされた場合に起こります。これがマスタで発生した場合、スレーブ
スレッドは終了し、データベース
アドミニストレータの指示を待機します。エラー
コードが正当で、クエリを実行したときに同一のエラー
コードがスレーブに返る場合はこの限りではありません。このエラー
コード検証の動作が望まれるものではない場合、--slave-skip-errors
オプションで固有化またはすべてのエラーをマークアウト
(無視) できます。
注意
トランザクションと非トランザクションの両テーブルを更新するレプリケーション環境では、このトランザクションは行わないでください。
スレーブ テーブルのコラム数が、それに対応しているマスタ テーブルのものより多い場合、マスタからスレーブへ複製できます。
Table T1 をマスタから、スレーブの T2 へ複製する場合、次の条件に従う必要があります。
行ベースのレプリケーションを使用する。
T1 と T2 は同一のデータベース名とテーブル名を持つ。
T2 には T1 よりもカラム数があっても、T1 のカラムに対応後、連続して表示されなければならない。
T1 と T2 で一致するすべてのカラムは同一のタイプである。
T1 ではなく、T2 のカラムすべてがデフォルト値である。
この機能は MySQL 5.1.12 に追加されました。
FOREIGN_KEY_CHECKS、SQL_MODE、UNIQUE_CHECKS、SQL_AUTO_IS_NULL
の変数はすべて複製可能です。これは MySQL 5.0
以来、実現しました。storage_engine
システム変数 (table_type) は、MySQL
5.1ではまだ複製できませんが、異なるストレージ
エンジン間での複製には適しています。
更新対象のテーブルのステートメントで使用する場合には、セッション変数を正確に複製することはできません。たとえば、INSERT
INTO mytable VALUES(@@MAX_JOIN_SIZE) に続く
SET MAX_JOIN_SIZE=1000
の場合は、マスタとスレーブに同一のデータを挿入できません。これは、INSERT
INTO mytable
VALUES(CONVERT_TZ(...,...,@@time_zone))に続く
SET TIME_ZONE=...
という一般的なシーケンスの場合には、この限りではありません。
セッション変数のレプリケーションは、行ベースのレプリケーションを使用している場合には干渉しません。詳細は 項5.1.2. 「レプリケーション フォーマット」 を参照してください。
MySQL 5.1 に実装したバイナリ
ログ形式は、以前のバージョンで使用していたものとは大きく異なり、キャラクタ
セットの処理、LOAD DATA
INFILE、タイム
ゾーンに関しては特に異なります。
一般的なルールとしては、マスタとスレーブを同じバージョンで実行しているときにレプリケーションを設定してください。(MySQL 5.1, 5.0 または 4.1 など)異なるバージョン間でレプリケーションを実行する必要がある場合は、クライアントにマスタと同等またはそれ以上のバージョンを使用していることを確認してください。(例: マスタで 4.1.23、スレーブで 5.0.24)
レプリケーションはMySQL 5.0 および 5.1 のマスタとサーバであれば、コンビネーションに関係なく、正確にできます。マスタとスレーブで異なるグローバル キャラクタ セットの変数を使用している場合や、マスタとスレーブで異なるグローバル タイム ゾーンの変数を使用している場合でも同様です。これはマスタとスレーブのどちらか、もしくはその両方がMySQL 4.1 以前を使用している場合には該当しません。
レプリケーションの互換性は継続的に向上するため、最新の MySQL バージョンを使用することをお勧めします。マスタとスレーブで同一のバージョンを使用することも効果的です。アルファまたはベータ バージョンをマスタとスレーブで使用している場合には、プロダクション バージョンにアップグレードすることをお勧めします。マスタで使用中のものが新しく、スレーブで使用中のものが古い場合にレプリケーションを行うと失敗するケースが多分にあります。一般的には、MySQL 5.1.x を実行しているスレーブは、マスタで使用しているバージョンが古い (MySQL 3.23、4.0 または 4.1) でも使用できますが、その逆の場合はできません。
注意
新しいバイナリ ログ形式のマスタから、古い形式を使用してるスレーブへ複製することはできません。 (例: MySQL 5.0 から MySQL 4.1 へ)項5.4.3. 「レプリケーション セットアップのアップグレード」に記載の通り、これは、レプリケーション サーバのアップグレードに大きな影響を与えます。
前項の情報はプロトコル レベルでのレプリケーション互換に関連します。しかし、SQL レベルでの互換性問題など、他にも制限があります。たとえば、複製したステートメントが5.0ではなく 5.1 で利用可能なSQLの機能を使用している場合は、5.1 のマスタは、5.0 のスレーブに複製できません。その問題に関しては、項5.4.1. 「レプリケーション機能と既知問題」を参照してください。
レプリケーション セットアップに関連するサーバをアップグレードする場合、アップグレード手順は使用中のサーバのバージョンおよびアップグレードしようとしているバージョンによって異なります。
この項は、MySQL 3.23、4.0 または 4.1 から MySQL 5.1 へのレプリケーションをアップグレードするときに該当します。4.0 のサーバは 4.0.3 以降である必要があります。
マスタを初期の MySQL リリース シリーズから 5.1 にアップグレードする場合、そのマスタのすべてのスレーブで同一の5.1.x リリースを使用していることを確認してください。そうでない場合は、まずスレーブをアップグレードしてください。それぞれのスレーブをアップグレードするには、まずスレーブらをシャットダウンし、それぞれを適切な 5.1.x にアップグレードし、再起動させ、複製を再開します。5.1 のスレーブは、アップグレード前に書き込まれたリレー ログを読み込むことができ、そこに含まれているステートメントを実行することができます。アップグレードが行われた後にスレーブによって作成されたリレーログは、5.1 形式です。
スレーブをアップグレードした後は、マスタをシャットダウンし、スレーブと同様にマスタを同一の 5.1.x リリースでアップグレードし、再起動します。5.1 のマスタは、アップグレード前に書き込まれたリレー ログを読み込むことができ、それらを 5.1 のスレーブに送信することができます。スレーブは、古い形式を認識し、それに応じて正確に処理します。アップグレード後にマスタによって作成されたバイナリ ログは、5.1 形式です。これも同様に、5.1 スレーブが認識します。
言い換えれば、MySQL 5.1 へアップグレードする際には特に注意することはありません。ただし、マスタを 5.1 にアップグレード可能な状態にする前に、スレーブが MySQL 5.1 である必要があります。ノート:5.1 から古いバージョンへダウングレード (格下げ) することはできません。5.1 のバイナリ ログまたはリレー ログでの処理が完了したことを確認してから、ダウングレードで先に進む前に、それらを削除してください。
レプリケーション セットアップを以前のバージョンにダウングレードすることは、ステートメント ベースから行ベースのレプリケーションに変更した後、あるいは最初に行ベースのステートメントが binlog に書き込まれた後にはできません。詳細は 項5.1.2. 「レプリケーション フォーマット」 を参照してください。
Questions
6.4.4.1: スレーブは常にマスタに接続している必要がありますか。
6.4.4.2: マスタをネットワーク化しなければ、レプリケーションを実行できませんか。
6.4.4.3: スレーブがマスタと比較してどれだけ遅れているかを知る方法はありますか。または、スレーブによって複製が行われた最後のクエリ日を知る方法はありますか。
6.4.4.4: スレーブが追いつくまでマスタの更新をブロックする方法はありますか。
6.4.4.5: 二方向レプリケーションをセットアップするときに注意する点はありますか。
6.4.4.6: レプリケーションを使用してシステムのパフォーマンスを改善する方法はありますか。
6.4.4.7: パフォーマンス改善レプリケーションを用いたアプリケーションを作成するときに、クライアントコードはどのように準備しますか。
6.4.4.8: MySQL のレプリケーションで、どれくらいのシステム パフォーマンスの向上が期待できますか、そしてそれはいつ行うものですか。
6.4.4.9: 冗長性と高可用性を実現するために、レプリケーションをどのように使用すればよいですか。
6.4.4.10: マスタ サーバのロギング形式が、ステートメント ベースまたは行ベースのどちらであるかを確かる方法はありますか。
6.4.4.11: スレーブが行ベースのレプリケーションを使用するように設定する方法はありますか。
6.4.4.12: スレーブのマシンへの複製で、GRANT および REVOKE のステートメントを抑制する方法はありますか。
6.4.4.13: 混在のオペレーティング システムでレプリケーションを実行できますか。(例:マスタが Linux、スレーブが Mac OS X と Windows の場合)
6.4.4.14: 混在のハードウェア アーキテクチャでレプリケーションを実行できますか。(マスタが 64-bit、スレーブが32-bit のマシンの場合など)
Questions and Answers
6.4.4.1: スレーブは常にマスタに接続している必要がありますか。
いいえ、その必要はありません。スレーブは何時間でも、あるいは何日間でもシャットダウンしておいたり、非接続にしておいても、再接続してマスタの更新に追いつくことができます。たとえば、マスタとスレーブの関係をダイヤルアップ リンクでセットアップし、リンクアップを散発的かつ短時間に設定できます。この場合、任意の時点でスレーブがマスタと同期している保証がないため、これに対応する特別な対策を投じてください。
この対策としては、スレーブに情報が複製されていない場合は、マスタからバイナリ ログを削除しないでください。非同期のレプリケーションは、スレーブが最後に読み込んだレプリケーション ステートメントのバイナリ ログを読み込みできる場合に限ります。
6.4.4.2: マスタをネットワーク化しなければ、レプリケーションを実行できませんか。
はい。マスタのネットワーク化してください。ネットワーク化できない場合は、スレーブがマスタに接続してバイナリ
ログを転送することができません。skip-networking
ルールがコンフィギュレーション
ファイルで実行可能になっているかどうかを確認してください。
6.4.4.3: スレーブがマスタと比較してどれだけ遅れているかを知る方法はありますか。または、スレーブによって複製が行われた最後のクエリ日を知る方法はありますか。
SHOW SLAVE STATUS の
Seconds_Behind_Master
カラムを参考にしてください。詳細は
項5.5.1. 「レプリケーション実装の詳細」
を参照してください。
スレーブの SQL
スレッドでマスタから読み込んだイベントを実行する場合、このスレッドは自らのタイムをイベントのタイムスタンプに修正します。ノート: TIMESTAMP
が十分に複製される理由はここにあります。SHOW
PROCESSLIST 出力の Time
カラムに表示される数字は、スレーブ SQL
スレッドに対する秒数であり、 最後に複製したイベントのタイムスタンプとスレーブ
マシンの実際の時刻の差です。これを使用して、最後に複製したイベントの日付を特定できます。注意:
スレーブがマスタから切断してから 1
時間後に再接続した場合、SHOW
PROCESSLIST の Time
カラムでスレーブ SQL スレッドが 3600
の値を表示する場合があります。これは、スレーブは
1
時間遅れたクエリを実行しているためです。(タイムスタンプから
1 時間経過している)
6.4.4.4: スレーブが追いつくまでマスタの更新をブロックする方法はありますか。
次の手順を使用します。
マスタで、次のコマンドを実行する。
mysql>
FLUSH TABLES WITH READ LOCK;mysql>SHOW MASTER STATUS;SHOWステートメントの出力からログファイル名とオフセットを記録する。スレーブで次のコマンドを実行する。ここで、
MASTER_POS_WAIT()関数の引数であるレプリケーション座標は、前のステップで記録した値。mysql>
SELECT MASTER_POS_WAIT('log_name',log_offset);指定のログ ファイルとオフセットにスレーブが到達するまで、
SELECTステートメントがブロックする。到達した時点でスレーブはマスタと同期して、ここでステートメントが戻る。マスタで次のステートメントを発行し、マスタによる更新処理の再開を許可する。
mysql>
UNLOCK TABLES;
6.4.4.5: 二方向レプリケーションをセットアップするときに注意する点はありますか。
MySQL レプリケーションでは、現在のところ、分散 (サーバ間の) 更新の原子性を保証するマスタとスレーブ間のロッキング プロトコルをサポートしていません。つまり、クライアント A が co-master 1 に更新を行い、それを co-master 2 に伝播する前に、クライアント B が co-master 2 に更新を行う場合、クライアント A の更新が co-master 1 で更新したものとは異なった更新になる可能性があります。この場合、co-master 2 からの更新すべてが伝播した後であっても、クライアント A の更新が co-master 2 に伝わるとき、co-master 1 とは異なるテーブルが生成されます。このため、どのような順序でも更新が安全に行われるという確証がある場合またはクライアントコードで更新順序の不正に対処できる場合以外では、二方向レプリケーションで 2 つのサーバをチェーン状に設定しないでください。
更新については、二方向レプリケーションは、それほどあるいはまったく、パフォーマンス向上には役立ちません。1 つのサーバで更新を行うときと同様に、どのサーバでも同等量での更新を行う必要があります。別のサーバから発生した更新が 1 つのスレーブ スレッドでシリアル化されるため、ロックの競合が少なくなる、という違いがあります。この利点も、ネットワーク遅延によっては相殺されてしまう可能性があります。
6.4.4.6: レプリケーションを使用してシステムのパフォーマンスを改善する方法はありますか。
1
つのサーバをマスタとしてセットアップし、書き込みのすべてをそこで直接行います。そして割当量とスペースが許容する限り多くのスレーブで構成し、マスタと複数のスレーブで読み取りを分散します。スレーブ側での速度を向上するには、--skip-innodb、--low-priority-updates
および --delay-key-write=ALL
でスレーブを起動することもできます。この場合、スレーブは
InnoDB
テーブルの代わりに非トランザクションの
MyISAM
テーブルを使用して、トランザクション
オーバーヘッドを取り除きながら、速度を上げます。
6.4.4.7: パフォーマンス改善レプリケーションを用いたアプリケーションを作成するときに、クライアントコードはどのように準備しますか。
スケール アウト ソリューションとしてレプリケーションを使用するためのガイドは、項5.3.3. 「スケールアウトのレプリケーション」 を参照してください。
6.4.4.8: MySQL のレプリケーションで、どれくらいのシステム パフォーマンスの向上が期待できますか、そしてそれはいつ行うものですか。
MySQL レプリケーションは、読み取りが頻繁に行われ、書き込みはそれほどでもないシステムに最も適しています。理論的には、単一のマスタや複数のスレーブのセットアップを使用することで、システムを拡張することができます。つまりネットワーク帯域幅を超えるか、更新負荷がマスタで処理しきれないポイントに到達するまでは、スレーブの数をシステムに追加できます。
追加する利点がなくなるまでいくつのスレーブを追加できるか、あるいはサイトのパフォーマンスをどれだけ向上できるかを判断するには、クエリ
パターンを知る必要があります。そして読み取りには毎秒ごとの読み取り、または
reads、書き取りには
writes
で、マスタとスレーブの通常のスループットの関係をベンチマークして、実証的に決定します。ここでは、例として、仮想システムのレプリケーションでの単純化した計算を示します。
システム負荷が 10% の書き込みと 90%
の読み取りで構成され、reads
が 1200 ? 2 × writes
であると仮定します。つまり、書き込みがなければシステムは毎秒
1,200
の読み取りを実行します。書き込みの平均は読み取り平均の
2 倍かかります。この関係はリニア (直線的)
です。マスタとそれぞれスレーブの能力は同じで、1
マスタと N
スレーブがあると想定します。それぞれのサーバ
(マスタまたはスレーブ)
は次のようになります。
reads = 1200 ? 2 × writes
reads = 9 × writes /
(
(読み取りは分散、書き込みはすべてのサーバへ)
N + 1)
9 × writes / (
N +
1) + 2 × writes = 1200
writes = 1200 / (2 +
9/(
N+1))
最後の数式は、N
スレーブ毎の最大数を示し、
ここでは、毎分 1,200
の可能な最大読み込み割合と書き込みあたり
9 の読み込み割合と仮定しています。
この分析は、次の結論を導き出します。
N= 0(レプリケーションがないことを意味する)の場合、システムは 1200/11、つまり毎秒 109 書き込みを処理できる(アプリケーションの性質上、読み取りが 9 倍になる)N= 1 の場合、毎秒 184 の書き込みまで処理可能N= 8 の場合、毎秒 400 の書き込みまで処理可能N= 17 の場合、毎秒 480 の書き込みまで処理可能Nが無限に近づくと(割当量も無限大に膨らみ)、毎秒 600 の書き込みに近くなり、システム スループットは 5.5 倍になる。しかし、8 サーバだけで 4 倍近くになる。
注意:
この計算ではシステム帯域を無限として想定しています。そのため、実際のシステムでは重要であるファクタを無視している可能性があります。多くの場合、N
アプリケーション
スレーブを追加した場合の結果を正確に予測するために、上記と同様の計算を行うことは適していません。このため、レプリケーションによってシステムのパフォーマンスが改善するかどうか、またどの程度改善するか、以下の質問の答えを参照して判断してください。
システムの読み取りと書き込みの比率
読み取りを減らした場合、1 つのサーバで処理できる書き込み負荷を増やせる程度
ネットワークの帯域幅を使用できるスレーブ数の上限
6.4.4.9: 冗長性と高可用性を実現するために、レプリケーションをどのように使用すればよいですか。
どのように冗長性を向上するかは、使用しているアプリケーションと状況により異なります。(自動フェールオーバを伴う) 高可用性ソリューションは、アクティブなモニタリングに加え、オリジナルのMySQL サーバからそのスレーブへのフェールオーバを行うためのカスタム スクリプトまたはサード パーティのツールのいずれかを必要とします。
この処理を手動で行うには、失敗したスレーブから事前構成のスレーブに移行できることを確認してください。(失敗時にアプリケーションとスレーブにマスタの変更を指示するスクリプトを作成する)。これを行うには、新たなサーバと通信するアプリケーションで代替するか、または、失敗したサーバから新たなサーバに MySQL サーバの DNS を調節します。
詳細とソリューション例に関しては 項5.3.6. 「フェイルオーバでのマスタ切り替え」 を参照してください。
6.4.4.10: マスタ サーバのロギング形式が、ステートメント ベースまたは行ベースのどちらであるかを確かる方法はありますか。
binlog_format
システム変数の値を確認します。
mysql> SHOW VARIABLES LIKE 'binlog_format';
その値は STATEMENT または
ROW のどちらかを示します。
6.4.4.11: スレーブが行ベースのレプリケーションを使用するように設定する方法はありますか。
スレーブは自動的にどちらの形式を使用するかを認識します。
6.4.4.12: スレーブのマシンへの複製で、GRANT および REVOKE のステートメントを抑制する方法はありますか。
サーバを
--replicate-wild-ignore-table=mysql.%
オプションで起動します。.
6.4.4.13: 混在のオペレーティング システムでレプリケーションを実行できますか。(例:マスタが Linux、スレーブが Mac OS X と Windows の場合)
はい、できます。
6.4.4.14: 混在のハードウェア アーキテクチャでレプリケーションを実行できますか。(マスタが 64-bit、スレーブが32-bit のマシンの場合など)
はい、できます。
指示に従って設定して、レプリケーションを設定しても機能しない場合は、エラー ログのメッセージをまず調べてください。多くの問題は、ログを調べることにより解決します。
エラー ログから問題の発生源が特定できない場合は、次の事柄を確かめます。
マスタのバイナリ ログで記録しているかどうかを、
SHOW MASTER STATUSで確認する。記録していれば、Positionはゼロ以外の値。記録してない場合、マスタの--log-binおよび--server-idで設定を確認する。スレーブが稼動しているかどうかを確認する。
SHOW SLAVE STATUSを実行し、Slave_IO_RunningおよびSlave_SQL_Runningの値が両方ともYesであることを確認する。Yes ではない場合、スレーブ サーバを起動するときのオプションを確認する。ヒント:--skip-slave-startは、START SLAVEクエリが出るまで、スレーブ スレッドの起動を抑制します。スレーブが稼動している場合は、マスタとの接続を確認する。
SHOW PROCESSLISTを実行して、I/O スレッドと SQL スレッドを見つけ、そのStateカラムでの表示を確認する。詳細は 項5.5.1. 「レプリケーション実装の詳細」を参照してください。I/O スレッドがConnecting to masterである場合は、次のことを確認する。レプリケーション ユーザのマスタでの権限を確認する。
マスタ ホスト名が正当であるかどうかを調べ、適切なポートでマスタと接続しているかどうかを確認する。レプリケーションに使用するポートはクライアント ネットワーク通信のものと同一。(デフォルトは
3306)ホスト名に関しては、適切な IP アドレスと対応しているかどうかを確認する。マスタ - スレーブ間のネットワーク接続が無効化しているかどうかを確認する。コンフィギュレーション ファイルで
skip-networkingオプションを調べる。ここでコメントがある、ない場合は完全に削除された可能性がある。マスタにファイアウォールもしくはIP フィルタのコンフィギュレーションなどを設定している場合は、MySQL で使用しているネットワーク ポートがフィルタされているかどうかを確認する。
pingもしくはtraceroute/tracertを使用して、マスタがホストに達しているかどうか確認する。
スレーブが以前は稼動していて、そして停止した場合は、マスタで実行されたステートメントがスレーブで失敗している可能性がある。ノート:これは、マスタの適切なスナップショットが行われている場合には発生しません。または、スレーブ スレッドの外側のスレーブでデータを修正しなければ発生することはありません。スレーブが不意に停止した場合、バグである可能性、または既存のレプリケーション障害である可能性がある。詳細は 項5.4.1. 「レプリケーション機能と既知問題」 を参照。ノート: 原因がバグによるものである場合は、項5.4.6. 「レプリケーション バグまたは問題を報告する方法」 を参照し、どのように報告するか指示に従ってください。
マスタで実行したステートメントがスデーブで実行できない場合は、次の手順に従う。それができない場合は、スレーブのデータベースを削除し、新たなスナップショットをマスタからコピーする方法で、データベースの全体的な再同期化を行う。
影響する可能性のあるスレーブのテーブルがマスタのテーブルとは異なるかどうかを判断する。これを処理することにより、なにが起こるか、なにが必要になるかを検討する。そして、マスタのテーブルと同一になるようスレーブのテーブルを作成し、
START SLAVEを実行する。前述のステップが機能しない、または適用されない場合は、必要に応じて、マニュアルでの更新を安全に実行できるかどうかを検討し、マスタから次に出されるステートメントを無視する。
マスタからの次のステートメントをスキップすると決めた場合は、以下のクエリを実行する。
mysql>
SET GLOBAL SQL_SLAVE_SKIP_COUNTER =mysql>N;START SLAVE;マスタから出される次のステートメントが
AUTO_INCREMENTまたはLAST_INSERT_ID()を使用しない場合は、Nの値は 1。そうでない場合は、その値は 2。ノート:AUTO_INCREMENTまたはLAST_INSERT_ID()を使用するステートメントの値が 2 である必要がある理由は、マスタのバイナリ ログで 2 イベントを処理するためです。スレーブがマスタと最初から完全に同期していた、そしてスレーブのスレッドの外側のテーブルを更新していないと確証できる場合は、バグによる不具合である可能性がある。ノート: 最新バージョンの MySQL を使用している場合は、その問題を報告してください。古いバージョンを使用している場合は、最新のプロダクション リリースにアップグレードし、それでもその問題が続くかどうかを確認する。
ユーザによるエラーではないことが確認でき、レプリケーションが全く機能しないまたは不安定である場合は、バグとして報告してください。バグ問題を解決するには、より多くの情報を必要とします。そのため、バグ報告を行う際には、時間をかけて、できるだけ詳細な情報を送信してください。
そのバグを実証する再現可能なテスト ケースがある場合には、項1.7. 「質問またはバグの報告」 を参照して、それをバグ用のデータベースに入れてください。「phantom」 問題 (説明できない問題など) の場合は、次の手順に従ってください。
ユーザによるエラーではないことを確認します。例:スレーブ スレッド外側のスレーブを更新する場合は、非同期のデータになり、更新時にユニーク キー制約である可能性があります。この場合、スレーブ スレッドは停止している状態で、それらを同期で持ち込むために、手動によるテーブルのクリーン アップを待機しています。これは、レプリケーションに関する問題ではありません。これは外部からの障害がレプリケーションの失敗に起因しているということです。
--log-slave-updatesおよび--log-binオプションでスレーブを実行します。これらのオプションでスレーブがマスタから受信する更新をスレーブのバイナリ ログに記録するようにします。レプリケーション状態をリセットする前にすべての証拠を保存します。ノート: この問題を解決するには、できるだけ多くの問題を控えておいてください。収集する必要がある証拠
マスタからのすべてのバイナリ ログ
スレーブからのすべてのバイナリ ログ
問題を認識した時点のマスタからの
SHOW MASTER STATUS出力問題を認識した時点のスレーブからの
SHOW SLAVE STATUS出力マスタおよびスレーブのエラー ログ
バイナリ ログを調べるには、mysqlbinlog を使用します。次に示すものは、問題があるステートメントを探し出すために役立ちます。
log_posおよびlog_fileは、SHOW SLAVE STATUSからのMaster_Log_FileおよびRead_Master_Log_Pos値です。shell>
mysqlbinlog -jlog_poslog_file| head
問題からの証拠を収集した後は、まず全く別のテスト ケースとして、それを隔離してください。そして、より多くの情報とともに、バグ用のデータベースに入れてください。詳細は 項1.7. 「質問またはバグの報告」 で参照してください。
レプリケーションのメカニズムは、
マスタサーバが使用中のデータベースへの変更
(更新、削除など)
を追跡し続け、マスタサーバのバイナリ
ログからクエリを読み込むということに基づきます。バイナリ
ログは、データベース化が開始された時点からの記録として、その役割を果たします。バイナリ
ログは、データベース
ストラクチャまたはストラクチャの保持データを編集または修正するクエリすべての記録を含みます。SELECT
ステートメントは、記録されません。同様にデータベースのデータまたはストラクチャも修正されません。
マスタに接続しているそれぞれのスレーブは、バイナリ ログのコピーを受信し、そのバイナリ ログ内のイベントを実行します。これには、元の クエリ (ステートメント) をリピートし、マスタで作成されたように変更する、ということです。マスタ元で実行したクエリに従って、テーブル作成またはストラクチャ修正、データの挿入、削除、更新が行われます。
それぞれのスレーブが独立しているため、マスタのバイナリ ログにあるクエリのリプレイを、マスタに接続しているそれぞれのスレーブで行います。さらに、それぞれのスレーブは、バイナリ ログをマスタに要求することによってコピーを受け取る、つまり、マスタがスレーブにデータを与える、というよりは、マスタからデータを取り込むため、スレーブはデータベースのコピーの読み取りおよび書き込みをスレーブのペースおよびレートで行います。そのため、データベースの最新情報を更新する際には、マスタまたはスレーブの処理能力を損なうことなく、複製プロセスの開始および停止ができます。
レプリケーションの実装に関する詳細は、項5.5.1. 「レプリケーション実装の詳細」を参照してください。
スレーブとマスタは、レプリケーション プロセスに関するステータスを定期的にレポートするため、処理状況の監視が可能です。スレーブの状態に関する詳細は、項5.5.3. 「スレーブ レプリケーションの I/O スレッド状態」 もしくは 項5.5.4. 「スレーブ レプリケーションの SQL スレッド状態」 を参照してください。マスタの状態に関する詳細は、項5.5.2. 「マスタレプリケーションのスレッド状態」 を参照してください。
マスタのバイナリ ログは、プロセスされる前に、スレーブのローカル リレー ログが記憶します。スレーブもまた、マスタのバイナリ ログおよびローカル リレーのログとの位置関係を記録します。詳細は、項5.5.5. 「レプリケーション リレーとステータス ファイル」 を参照してください。
クエリ評価をコントロールする変数およびコンフィギュレーションのオプションに従って適用されたルールの組み合わせを基に、データベースとテーブルの更新はスレーブで行います。これらのルールがどのように適用されるかに関しては、項5.5.6. 「サーバのレプリケーション ルール評価」 を参照してください。
MySQL レプリケーションには 3
つのスレッドが関連しています。マスタには 1
スレッド、スレーブでは2つのスレッドがあります。START
SLAVE ステートメントが発行されると、I/O
スレッドがスレーブに作成されます。このスレッドはマスタに接続し、マスタのバイナリ
ログに記録されているクエリの送信を要求します。そして、マスタが、そのバイナリ
ログを送信するために、スレッドを作成します。このスレッドは、マスタの
SHOW PROCESSLIST 出力で Binlog
Dump として確認できます。スレーブの I/O
スレッドは、マスタの Binlog Dump
スレッドが送信するアップデートを読み取り、それをスレーブのデータ
ディレクトリにあるrelay logs
と呼ばれるローカル
ファイルにコピーします。そして、スレーブがリレー
ログを読み取りそれに含まれるクエリを実行するために、3
つ目の スレッドである SQL
スレッドを作成します。
マスタとスレーブ間の 1 接続につき、3 つのスレッドがあります。つまり、マスタには複数のスレーブがあり、マスタは接続したスレーブごとにスレッドを作成します。そして、このスレーブには I/O スレッドおよび SQL スレッドの両方が存在します。
スレーブは2つのスレッドを使い、マスタからのアップデートを読み取りと実行を 2 つの独立したタスクに区切ります。これにより、クエリの実行が遅い場合でも、クエリの読み取りというタスクが遅くなることはありません。たとえば、スレーブ サーバが一時的に稼動していない場合に、SQL スレッドが遅れていたとしても、スレーブが起動するときに は、I/O スレッドがマスタのすべてのバイナリ ログ内容をすばやく取り出します。つまり、SQL スレッドが取り出したクエリのすべてを実行し終える前にスレーブが停止する場合でも、I/O スレッドの方ですべてを取り出しているため、クエリのコピーがスレーブのリレー ログで安全に格納されていることになり、スレーブが起動するときには、そのクエリを実行する準備ができているということです。このため、マスタはスレーブの読み出しを待つ必要がなくなり、マスタサーバがマスタ元のバイナリ ログをより早く削除することを可能にします。
SHOW PROCESSLIST
ステートメントを使用すると、レプリケーションに関するマスタ側およびスレーブ側での処理内容を確認できます。以下で、SHOW
PROCESSLIST. の出力で、この 3
つのスレッドがどのように表示されるかを例示します。
マスタサーバでは、SHOW PROCESSLIST
の出力は以下のようになります。
mysql> SHOW PROCESSLIST\G
*************************** 1. row ***************************
Id: 2
User: root
Host: localhost:32931
db: NULL
Command: Binlog Dump
Time: 94
State: Has sent all binlog to slave; waiting for binlog to
be updated
Info: NULL
ここで、スレッド Id 2 は 接続したスレーブの
Binlog Dump レプリケーション
スレッドです。State
の情報は、すべてのアップデート (更新情報)
がスレーブに送信されたことを示し、マスタは次の更新情報を待機している状態です。マスタサーバの
Binlog Dump
スレッドが表示されない場合は、このレプリケーションは実行されていないことを意味します。?つまり、この時点でスレーブが接続されていないということです。
スレーブ サーバでは、SHOW PROCESSLIST
の出力は以下のようになります。
mysql> SHOW PROCESSLIST\G
*************************** 1. row ***************************
Id: 10
User: system user
Host:
db: NULL
Command: Connect
Time: 11
State: Waiting for master to send event
Info: NULL
*************************** 2. row ***************************
Id: 11
User: system user
Host:
db: NULL
Command: Connect
Time: 11
State: Has read all relay log; waiting for the slave I/O
thread to update it
Info: NULL
この情報は、 スレッド Id 10 が I/O
スレッドであり、マスタサーバと通信していることを示し、スレッド
Id 11 は SQL スレッドであり、 リレー ログ
に格納されたアップデートを処理中であることを示します。SHOW
PROCESSLIST
が実行された場合、スレッドの両方がアイドル状態であり、次のアップデートを待機しています。
Time
カラムの値は、マスタと比較した場合に、スレーブがどれくらい遅れているかを示します。詳しくは
項5.4.4. 「レプリケーション FAQ」 を参照してください。
以下の一覧は、マスタの Binlog Dump
スレッドの State
カラムに表示される一般的な状態です。Binlog
Dump
スレッドがマスタサーバに表示されない場合、このレプリケーションは実行されていないことを意味します。?
つまり、この時点でスレーブは接続していないということです。
Sending binlog event to slaveバイナリ ログはクエリなどの情報を組み合わせたイベントを含む。バイナリ ログからのイベントを読み取り、その内容をスレーブに送信中であることを示す状態。
Finished reading one binlog; switching to next binlogバイナリ ログ ファイルの読み取りを完了し、スレーブに送信する次のファイルを開いている状態。
Has sent all binlog to slave; waiting for binlog to be updated Info:すべてのバイナリ ログ ファイルからのアップデートの読み取りを完了し、スレーブそれを送信した状態。マスタで発生中のアップデートの結果から新たなイベントがバイナリ ログに出ることを待機しているアイドル状態。
Waiting to finalize terminationスレッド停止中に発生する一時的な状態。
以下の一覧は、スレーブの I/O スレッドの
State
カラムに表示される一般的な状態です。これは、SHOW
SLAVE STATUS 出力の Slave_IO_State
カラムにも表示され、このステートメントを使用して現状を把握できます。
Connecting to masterマスタへの接続を試行中の状態。
Checking master versionマスタへの接続が確立した直後に発生する瞬間的な状態。
Registering slave on masterマスタへの接続が確立した直後に発生する瞬間的な状態。
Requesting binlog dumpマスタへの接続が確立した直後に発生する瞬間的な状態。マスタにバイナリ ログの内容を送信するよう要求している状態。要求したバイナリ ログのファイル名と位置を最初に要求する。
Waiting to reconnect after a failed binlog dump request接続切断などにより、バイナリ ログ ダンプ要求に失敗した場合の状態。スレッドはスリープ中この状態になり、定期的に再接続を試みる。ノート:
--master-connect-retryオプションを使用して、再接続のインターバルを設定できます。Reconnecting after a failed binlog dump requestマスタへの再接続を試行中の状態。
Waiting for master to send event Master_Host:マスタへの接続を完了し、バイナリ ログ イベントの到達を待機している状態。ノート: マスタがアイドル状態の場合には、この状態の待機時間は長くなり。
slave_net_timeout秒継続した場合、タイムアウトになります。そのときには接続切断とみなされ、スレッドは再接続を試行します。Queueing master event to the relay logイベントの読み取りが完了し、SQL スレッドで処理できるように、読み取ったイベントをリレー ログにコピー中の状態。
Waiting to reconnect after a failed master event read接続切断などが原因で、読み取り中にエラーが発生した状態。再接続が試行される前に、
master-connect-retry秒間、スリープ状態になる。Reconnecting after a failed master event readスレッドがマスタへの再接続を試行中の状態。再び接続が確立されると、
Waiting for master to send eventの状態になる。Waiting for the slave SQL thread to free enough relay log space0 以外の
relay_log_space_limit値を使用しているため、合計サイズがその値を超えるまでに、リレー ログが過大した状態。I/O スレッドはリレー ログ ファイルの一部を削除するために、リレー ログ内容を処理しながら、SQL スレッドに領域余裕ができるのを待機している状態。Waiting for slave mutex on exitスレッド停止中に発生する一時的な状態。
以下の一覧は、スレーブの SQL スレッドの
State
カラムに表示される一般的な状態です。
Reading event from the relay logイベントを処理するために、そのイベントをリレー ログから読み取っている状態。
Has read all relay log; waiting for the slave I/O thread to update itリレー ログ ファイルのイベントをすべて処理し、I/O スレッドが新たなイベントがリレー ログに書き込むことを待機している状態。
Waiting for slave mutex on exitスレッド停止中に発生する一時的な状態。
I/O スレッドの State
カラムはクエリ文字列を表示する場合があります。これは、スレッドがリレー
ログからイベントを読み取り、クエリを抽出して、そのクエリを実行中であることを示します。
レプリケーション中にMySQL サーバは、マスタからリレーされたバイナリ ログの保持に使うファイルをいくつか作成し、リレーされたログ内からステータスと位置に関する情報を記録します。このプロセスでは 3 種類のファイル タイプを使用します。
relay log は、マスタのバイナリ ログから読み込まれたイベントから成る。バイナリ ログのイベントは、レプリケーション スレッドの一環としてスレーブで実行する。
master.info ファイルはステータスやスレーブがマスタへ接続する際のコンフィギュレーション情報を含む。このファイルは、マスタのホスト名、ログイン資格情報、そしてマスタのバイナリ ログ内の現状位置に関する情報を保持する。
relay.info ファイルは、スレーブのリレー ログ ファイル内の実行ポイントに関するステータス情報を保持する。
以下は、この 3
種類のファイルとレプリケーション
プロセスの関係です。master.info
ファイルは、マスタ バイナリ
ログ内のポイントを保持し、このログはマスタからの読み込みです。そのリレー
ログにこの読み出されたイベントを記憶します。relay.info
ファイルは、リレー
ログ内にあるクエリの位置を記録し、このクエリは実行済みです。
リレー ログのファイル名はデフォルトで
host_name-relay-bin.nnnnnnhost_name
はスレーブ サーバ
ホスト名、nnnnnn
の部分はシーケンス番号です。連続するリレー
ログ
ファイルは、連続するシーケンス番号になり、この番号は
000001
で始まります。スレーブはインデックス
ファイルを使用して、使用中のリレー ログ
ファイルを追跡します。リレー
ログのインデックス
ファイル名はデフォルトで、host_name-relay-bin.index
スレーブ サーバは、リレー ログ
ファイルをデータ
ディレクトリにデフォルトで作成します。デフォルトのファイル名は、--relay-log
および --relay-log-index の各サーバ
オプションで上書きできます。詳しくは
項5.1.3. 「レプリケーションのオプションと変数」
を参照してください。
リレー ログはバイナリ
ログと同様のフォーマットであるため、mysqlbinlog
を使用して読み取れます。SQL
スレッドは、ファイル内のイベントをすべて実行した後、不要になったリレー
ログ ファイルを自動的に削除します。SQL
スレッドがこの作業を行うため、リレー
ログ削除のコマンドは不要です。ただし、FLUSH
LOGS がリレー
ログをローテートする場合は、SQL
スレッドがそれらを削除するタイミングに影響します。
以下の条件で、スレーブ サーバは新たなリレー ログ ファイルを作成します。
(スレーブサーバの起動後、最初に) I/O スレッドが開始された場合
ログをフラッシュ (一括書き出し) する場合。例:
FLUSH LOGSまたは mysqladmin flush-logsその時点でのリレー ログ ファイルのサイズが過大化した場合以下は、「過大化」 の定義。
max_relay_log_size> 0 の場合 (この値はファイル サイズの最大値)max_relay_log_size= 0 の場合 (max_binlog_sizeはファイル サイズの最大値を決定)
スレーブ レプリケーション サーバは、データ
ディレクトリに ファイルを2
つ作成します。これらのファイルは
status files (ステータス ファイル)
と呼ばれ、デフォルトで
master.info および
relay-log.info
というファイル名です。このデフォルトのファイル名は
--master-info-file および
--relay-log-info-file
オプションを使用して変更できます。詳しくは
項5.1.3. 「レプリケーションのオプションと変数」
を参照してください。
この 2 つ のステータス ファイルは、SHOW
SLAVE STATUS
ステートメントの出力に表示される情報を含みます。(コマンドの説明については
項12.6.2. 「スレーブ サーバをコントロールする SQL
ステートメント」
を参照)スタータス
ファイルはディスクに保存されるため、スレーブ
サーバがシャットダウンした場合でも保持されます。そのため、次回にスレーブが起動する際には、スレーブがこの
2 つのファイル (マスタのバイナリ ログおよび
スレーブ自体のリレー ログ)
から前回の進み具合を読み取ります。
I/O スレッドは master.info
ファイルを更新します。以下のテーブルは、ファイル内のライン
(行) と SHOW SLAVE STATUS
で表示されるカラムの対応表です。
| 行 | カラム ステータス | 説明 |
| 1 | ? | ファイル内のライン番号 |
| 2 | Master_Log_File | マスタのバイナリ ログ名。このログはその時点でマスタ側から読み込み中。 |
| 3 | Read_Master_Log_Pos | マスタのバイナリ ログ内の現在位置。その時点分のマスタの読み込みは完了している。 |
| 4 | Master_Host | マスタのホスト名 |
| 5 | Master_User | マスタに接続するためのユーザ名 |
| 6 | パスワード (SHOW SLAVE STATUS
では表示されない) | マスタに接続するためのパスワード |
| 7 | Master_Port | マスタに接続するためのネットワーク ポート |
| 8 | Connect_Retry | インターバル時間(秒)。スレーブがマスタに再接続を試行する際に待機する時間 |
| 9 | Master_SSL_Allowed | サーバが SSL 接続をサポートするかどうかを示す |
| 10 | Master_SSL_CA_File | 証明機関 (Certificate Authority) に使用したファイル |
| 11 | Master_SSL_CA_Path | 証明機関 (CA) へのパス |
| 12 | Master_SSL_Cert | SSL 証明のファイル名 |
| 13 | Master_SSL_Cipher | SSL 接続に使用している暗号法 (サイファ) 名 |
| 14 | Master_SSL_Key | SSL キー ファイル名 |
SQL スレッドは relay-log.info
ファイルを更新します。以下のテーブルは、ファイル内のライン
(行) と SHOW SLAVE STATUS
で表示されるカラムの対応表です。
| 行 | スタータス カラム | 説明 |
| 1 | Relay_Log_File | 現行のリレー ログ ファイル名 |
| 2 | Relay_Log_Pos | リレー ログ ファイル内の現在位置。この位置までのイベントはスレーブのデータベースで実行済み。 |
| 3 | Relay_Master_Log_File | マスタの (リレー ログ ファイルで読み取られたイベントの) バイナリ ログ ファイル名 |
| 4 | Exec_Master_Log_Pos | (既に実行されたイベントの) マスタのバイナリ ログ ファイル内の対応位置 |
注意:relay-log.info
ファイルをディスクにフラッシュしていない場合、SHOW
SLAVE STATES コマンド表示のステート
(状態) および relay-log.info
ファイルの内容が一致しない可能性があります。スレーブの
relay-log.info
はオフラインのときにだけ閲覧することをお勧めします。
(mysqld
が稼動していないときなど)システムが稼動している場合は、SHOW
SLAVE STATUS を使用してください。
マスタサーバ がバイナリ ログにステートメント (クエリ) を記憶しない場合、ステートメントは複製されません。サーバがステートメント (クエリ) をログする場合、そのステートメントはすべてのスレーブに送信されます。そして、それぞれのスレーブ (受信側) が受信したステートメントを実行するかどうかを決めます。
ノート:バイナリへのログをコントロールするには、--binlog-do-db
および --binlog-ignore-db
のオプションを使用して、どのデータベースがバイナリ
ログにイベントを書き込むかをマスタでコントロールできます。これらのオプションを評価する際にサーバが使用するルールの詳細は、項4.11.4. 「バイナリ ログ」
を参照してください。注意:スレーブで実行しているイベントをコントロールするには、スレーブにフィルターを使います。複製されたデータベースおよびテーブルをコントロールする目的で、これらのオプションを使用しないでください。
スレーブ側では、マスタから受信したクエリを実行するかどうかの決定は、スレーブ起点の
--replicate-* オプション (ルール)
に従って行われます。(項5.1.3. 「レプリケーションのオプションと変数」を参照してください。)以下の手順に従い、スレーブはこれらのオプションを評価します。最初に、データベース
レベルのオプションを比較し、続いてテーブル
レベルのオプションを比較します。
--replicate-*
オプションがないなど、ルールが単純な場合は、この手順により、スレーブがマスタから受信するすべてのクエリを実行するという結果を生成します。それ以外には、この結果は設定オプションに依存します。ノート:「do」
および 「ignore」
のオプション、またはワイルド
カードなどのオプションの混在を避けることで、ルール
セットの設定効果を決定する作業が簡素化します。
ステージ 1. データベース オプションの評価
このステップでは、データベース設定を特定する--replicate-do-db
または --replicate-ignore-db
ルールがあるかどうかを、スレーブが確認します。
No:クエリを許可して、テーブル比較のステップへ進む。
Yes:クエリを許可もしくは無視する決定を行うために、
--binlog-do-dbおよび--binlog-ignore-dbのオプションと同様のルールを使用して、オプションをテストする。(以下の選択をするために) テスト結果を確認する。Permit:すぐには実行しない。決定を保留して、テーブル比較ステップに進む。
Ignore:クエリを無視して終了する。
このステージでは、後続のオプション確認するという目的で、クエリを許可または無視するようになります。そのため、クエリは許可されますが、実際にはまだ実行されません。後続のステージで、テーブル オプションを比較するステップへ進みます。
ステージ 2. テーブル オプションの評価
最初に、前段階として、スレーブ側でクエリ ベースのレプリケーションが可能かどうかをテストします。それが可能であり、格納された機能内でクエリが発生する場合、そのクエリを実行して、終了します。メモ: 行ベースのレプリケーションを可能にした場合、スレーブ側はマスタ内の格納機能でクエリが発生したことを知らないため、その条件は有効になりません。
次に、スレーブ側でテーブル オプションをテストし、それらを評価します。サーバがこのポイントに達する際に、テーブルにオプションがない場合、サーバはすべてのクエリを実行します。テーブルに 「do」 ルールが複数ある場合には、実行するクエリはそのテーブルのルールのうち 1 つと一致する必要があります。一致しない場合は、無視されます。「ignore」 ルールが複数ある場合、 「ignore」 ルールに一致するものを除き、すべてのクエリが実行されます。以下のステップで、この評価の手順を説明します。
--replicate-*-tableルールはあるかNo:テーブルに制限がない。すべてのクエリが一致する。クエリを実行して、終了する。
Yes:テーブルに制限がある。更新対象のテーブルと既存ルールを比較する。複数のテーブルを更新する可能性がある。次のステップで、それぞれのテーブルに一致するルールを探す。ノート:この場合、クエリ ベースまたは行ベースのどちらでレプリケーションが可能になるかによって、その後の動作は左右されます。
クエリ ベースのレプリケーション:次のステップに進み、表示された順序でテーブル ルールの評価を開始する。 (注意:最初にノン ワイルド、続いて、ワイルド)更新対象のテーブルだけがルールと比較される。(例: クエリが
INSERT INTO sales SELECT * FROM pricesの場合、salesだけがルールとの比較対照)複数のテーブル (マルチ テーブルのクエリ) が更新対象の場合、「do」 または 「ignore」 で一致する最初のテーブルが比較される。つまり、サーバ側は、最初のテーブルをルールと比較する。その比較で、決定できない場合は、2番目のテーブルがルールとの照合になる。行ベースのレプリケーション:テーブル行すべての変更は別々にフィルタにかかる。対象テーブルが複数の場合、それぞれのテーブルが別々に、ルールに従ってフィルタにかかる。ルールと変更内容をよっては、更新が実行される部分と実行しない部分がある。行ベースのレプリケーションでは、クエリ ベースのレプリケーションで正確に複製されないケースを正確に処理する。以下は、
fooデータベースのテーブルを複製する必要があると仮定した場合の例。mysql>
USE bar;mysql>INSERT INTO foo.sometable VALUES (1);
--replicate-do-tableルールはあるかNo:次のステップへ進む。
Yes:テーブルはどれかと一致するか。
No:次のステップへ進む。
Yes:クエリを実行して、終了する。
--replicate-ignore-tableルールはあるか。No:次のステップへ進む。
Yes:テーブルはどれかと一致するか。
No:次のステップへ進む。
Yes:クエリを無視して、終了する。
--replicate-wild-do-tableルールはあるか。No:次のステップへ進む。
Yes:テーブルはどれかと一致するか。
No:次のステップへ進む。
Yes:クエリを実行して、終了する。
--replicate-wild-ignore-tableルールはあるか。No:次のステップへ進む。
Yes:テーブルはどれかと一致するか。
No:次のステップへ進む。
Yes:クエリを無視して、終了する。
--replicate-*-tableルールはどれにも一致しなかった。これらのルールでテストするテーブルはほかにあるか。No:すべての対象テーブルをテストしたが、どのルールにも一致しない。
--replicate-do-tableまたは--replicate-wild-do-tableルールはあるかNo:テーブルの 「do」 ルールがない。ゆえに 「do」 との明確な一致は不要。クエリを実行して、終了する。
Yes:テーブルに 「do」 ルールがある。それと明確に一致したものだけでクエリを実行。クエリを無視して、終了する。
Yes:ループする。
例:
--replicate-*ルールがまったくない。スレーブは、マスタから受信するすべてのクエリを実行する。
--replicate-*-dbルールはあるが、テーブル ルールがない。スレーブはデータベースのルールを使用して、クエリを許可または無視する。そしてテーブルでの制限がないので、スレーブはデータベースのルールによって許可したすべてのクエリを実行する。
--replicate-*-tableルールはあるが、データベース ルールがないデータベースに条件がないため、すべてのクエリがデータベース比較の段階で許可される。スレーブは、テーブルのルールを基にすべてのクエリを実行または無視する。.
データベースとテーブルのルールが混在する場合。
スレーブはデータベースのルールを使用して、クエリを許可または無視する。そして、テーブルのルールに従って、スレーブはデータベースのルールで許可したすべてのクエリを実行する。場合によって、このプロセスは直感に反する結果のようなものを生成する可能性があります。その場合、以下のルール セットを検討する。
[mysqld] replicate-do-db = db1 replicate-do-table = db2.mytbl2
db1がデフォルトのデータベースであり、スレーブがクエリを受信する場合。INSERT INTO mytbl1 VALUES(1,2,3);
このデータベース
db1は、データベース比較の段階で、--replicate-do-dbルールに一致します。よって、アルゴリズムはテーブル比較の段階でプロセスされます。テーブルのルールがない場合、クエリは実行されます。ルールには 「do」 のテーブル ルールが含まれるため、クエリを実行する場合は、そのクエリが一致するものである必要があります。この場合のクエリは、一致しないため、無視されます。db1のどのテーブルでも同様の場合があります。